Erros comuns de Go
The Coder Cafe
Se você gostou do meu livro, talvez se interesse pelo meu novo projeto: The Coder Cafe, uma newsletter diária para programadores.
Feeling overwhelmed by the endless stream of tech content? At The Coder Cafe, we serve one essential concept for coders. Written by a senior software engineer at Google, it's perfectly brewed for your morning coffee, helping you grow your skills deeply.

Esta página é um resumo dos erros do 100 Go Mistakes and How to Avoid Them book. Enquanto isso, também está aberto à comunidade. Se você acredita que um erro comum do Go deve ser adicionado, crie uma issue.
Beta
Você está visualizando uma versão beta enriquecida com muito mais conteúdo. No entanto, esta versão ainda não está completa e estou procurando voluntários para me ajudar a resumir os erros restantes (GitHub issue #43).
Progresso:
Código e Organização do Projeto
Sombreamento não intencional de variável (#1)
TL;DR
Evitar variáveis sombreadas pode ajudar a evitar erros, como fazer referência à variável errada ou confundir os desenvolvedores.
O sombreamento de variável ocorre quando um nome de variável é redeclarado em um bloco interno, mas essa prática está sujeita a erros. A imposição de uma regra para proibir variáveis obscuras depende do gosto pessoal. Por exemplo, às vezes pode ser conveniente reutilizar um nome de variável existente, como err no caso de erros. Porém, em geral, devemos ser cautelosos porque agora sabemos que podemos enfrentar um cenário onde o código compila, mas a variável que recebe o valor não é a esperada.
Código aninhado desnecessário (#2)
TL;DR
Evitar níveis aninhados e manter o caminho feliz alinhado à esquerda facilita a construção de um modelo de código mental.
Em geral, quanto mais níveis aninhados uma função exigir, mais complexa será sua leitura e compreensão. Vamos ver algumas aplicações diferentes desta regra para otimizar a legibilidade do nosso código:
- Quando um bloco
ifretorna, devemos omitir oelseem todos os casos. Por exemplo, não deveríamos escrever:
Em vez disso, omitimos o bloco else assim:
- Também podemos seguir esta lógica com um caminho não feliz:
Aqui, um s vazio representa o caminho não feliz. Portanto, devemos inverter a condição assim:
Escrever código legível é um desafio importante para todo desenvolvedor. Esforçar-se para reduzir o número de blocos aninhados, alinhar o caminho feliz à esquerda e retornar o mais cedo possível são meios concretos para melhorar a legibilidade do nosso código.
Uso indevido de funções init (#3)
TL;DR
Ao inicializar variáveis, lembre-se de que as funções init têm tratamento de erros limitado e tornam o tratamento de estado e os testes mais complexos. Na maioria dos casos, as inicializações devem ser tratadas como funções específicas.
Uma função init é uma função usada para inicializar o estado de um aplicativo. Não aceita argumentos e não retorna nenhum resultado (uma função func()). Quando um pacote é inicializado, todas as declarações de constantes e variáveis do pacote são avaliadas. Então, as funções init são executadas.
As funções de inicialização podem levar a alguns problemas:
- Elas podem limitar o gerenciamento de erros.
- Elas podem complicar a implementação de testes (por exemplo, uma dependência externa deve ser configurada, o que pode não ser necessário para o escopo dos testes unitários).
- Se a inicialização exigir que definamos um estado, isso deverá ser feito por meio de variáveis globais.
Devemos ser cautelosos com as funções init. No entanto, elas podem ser úteis em algumas situações, como na definição de configuração estática. Caso contrário, e na maioria dos casos, devemos tratar as inicializações através de funções ad hoc.
Uso excessivo de getters e setters (#4)
TL;DR
Forcing the use of getters and setters isn’t idiomatic in Go. Being pragmatic and finding the right balance between efficiency and blindly following certain idioms should be the way to go.
O encapsulamento de dados refere-se a ocultar os valores ou o estado de um objeto. Getters e setters são meios de habilitar o encapsulamento, fornecendo métodos exportados sobre campos de objetos não exportados.
No Go, não há suporte automático para getters e setters como vemos em algumas linguagens. Também não é considerado obrigatório nem idiomático o uso de getters e setters para acessar campos struct. Não devemos sobrecarregar nosso código com getters e setters em structs se eles não trouxerem nenhum valor. Deveríamos ser pragmáticos e nos esforçar para encontrar o equilíbrio certo entre eficiência e seguir expressões que às vezes são consideradas indiscutíveis em outros paradigmas de programação.
Lembre-se de que Go é uma linguagem única projetada para muitas características, incluindo simplicidade. No entanto, se encontrarmos necessidade de getters e setters ou, como mencionado, prevermos uma necessidade futura e ao mesmo tempo garantirmos a compatibilidade futura, não há nada de errado em usá-los.
Interface poluidas (#5)
TL;DR
Abstrações devem ser descobertas, não criadas. Para evitar complexidade desnecessária, crie uma interface quando precisar dela e não quando você prevêr que será necessária, ou se puder pelo menos provar que a abstração é válida.
Leia a seção completa aqui.
Interface do lado do producer (#6)
TL;DR
Manter interfaces no lado do cliente evita abstrações desnecessárias.
As interfaces são satisfeitas implicitamente em Go, o que tende a ser um divisor de águas em comparação com linguagens com implementação explícita. Na maioria dos casos, a abordagem a seguir é semelhante à que descrevemos na seção anterior: as abstrações devem ser descobertas, não criadas. Isso significa que não cabe ao producer forçar uma determinada abstração para todos os clientes. Em vez disso, cabe ao cliente decidir se precisa de alguma forma de abstração e então determinar o melhor nível de abstração para suas necessidades.
Uma interface deve residir no lado do consumidor na maioria dos casos. Contudo, em contextos específicos (por exemplo, quando sabemos – e não prevemos – que uma abstração será útil para os consumidores), podemos querer tê-la do lado do procuder. Se o fizermos, devemos nos esforçar para mantê-lo o mínimo possível, aumentando o seu potencial de reutilização e tornando-o mais facilmente combinável.
Interfaces de retorno (#7)
TL;DR
Para evitar restrições em termos de flexibilidade, uma função não deve retornar interfaces, mas implementações concretas na maioria dos casos. Por outro lado, uma função deve aceitar interfaces sempre que possível.
Na maioria dos casos, não devemos retornar interfaces, mas implementações concretas. Caso contrário, isso pode tornar nosso design mais complexo devido às dependências do pacote e pode restringir a flexibilidade porque todos os clientes teriam que contar com a mesma abstração. Novamente, a conclusão é semelhante às seções anteriores: se sabemos (não prevemos) que uma abstração será útil para os clientes, podemos considerar o retorno de uma interface. Caso contrário, não deveríamos forçar abstrações; eles devem ser descobertas pelos clientes. Se um cliente precisar abstrair uma implementação por qualquer motivo, ele ainda poderá fazer isso do lado do cliente.
any não diz nada (#8)
TL;DR
Use apenas any se precisar aceitar ou retornar qualquer tipo possível, como json.Marshal. Caso contrário, any não fornece informações significativas e pode levar a problemas de tempo de compilação, permitindo que um chamador chame métodos com qualquer tipo de dados.
O tipo any pode ser útil se houver uma necessidade genuína de aceitar ou retornar qualquer tipo possível (por exemplo, quando se trata de empacotamento ou formatação). Em geral, devemos evitar a todo custo generalizar demais o código que escrevemos. Talvez um pouco de código duplicado possa ocasionalmente ser melhor se melhorar outros aspectos, como a expressividade do código.
Ficar confuso sobre quando usar genéricos (#9)
TL;DR
Depender de parâmetros genéricos e de tipo pode impedir a gravação de código clichê (boilerplate) para fatorar elementos ou comportamentos. No entanto, não use parâmetros de tipo prematuramente, mas somente quando você perceber uma necessidade concreta deles. Caso contrário, introduzem abstrações e complexidade desnecessárias.
Leia a seção completa aqui.
Não estar ciente dos possíveis problemas com a incorporação de tipos (#10)
TL;DR
Usar a incorporação de tipo (type embedding) também pode ajudar a evitar código clichê (boilerplate); no entanto, certifique-se de que isso não leve a problemas de visibilidade onde alguns campos deveriam ter permanecido ocultos.
Ao criar uma struct, Go oferece a opção de incorporar tipos. Mas isso às vezes pode levar a comportamentos inesperados se não compreendermos todas as implicações da incorporação de tipos. Ao longo desta seção, veremos como incorporar tipos, o que eles trazem e os possíveis problemas.
No Go, um campo struct é chamado de incorporado se for declarado sem nome. Por exemplo,
Na estrutura Foo, o tipo Bar é declarado sem nome associado; portanto, é um campo incorporado.
Usamos incorporação para promover os campos e métodos de um tipo incorporado. Como Bar contém um campo Baz, esse campo é promovido para Foo. Portanto, Baz fica disponível a partir de Foo.
O que podemos dizer sobre a incorporação de tipos? Primeiro, observemos que raramente é uma necessidade e significa que, qualquer que seja o caso de uso, provavelmente também poderemos resolvê-lo sem incorporação de tipo. A incorporação de tipos é usada principalmente por conveniência: na maioria dos casos, para promover comportamentos.
Se decidirmos usar incorporação de tipo, precisamos ter em mente duas restrições principais:
- Não deve ser usado apenas como um açúcar sintático para simplificar o acesso a um campo (como
Foo.Baz()em vez deFoo.Bar.Baz()). Se esta for a única justificativa, não vamos incorporar o tipo interno e usar um campo. - Não deve promover dados (campos) ou um comportamento (métodos) que queremos ocultar do exterior: por exemplo, se permitir que os clientes acessem um comportamento de bloqueio que deve permanecer privado da struct.
Usar a incorporação de tipo de forma consciente, mantendo essas restrições em mente, pode ajudar a evitar código clichê (boilerplate) com métodos de encaminhamento adicionais. No entanto, vamos garantir que não o fazemos apenas por motivos cosméticos e não promovemos elementos que deveriam permanecer ocultos.
Não usar o padrão de opções funcionais (functional options pattern) (#11)
TL;DR
Para lidar com opções de maneira conveniente e amigável à API, use o padrão de opções funcionais.
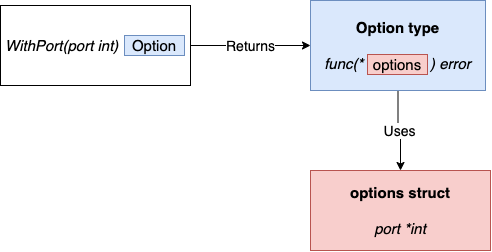
Embora existam diferentes implementações com pequenas variações, a ideia principal é a seguinte:
- Uma estrutura não exportada contém a configuração: opções.
- Cada opção é uma função que retorna o mesmo tipo:
type Option func(options *options) error. Por exemplo,WithPortaceita um argumentointque representa a porta e retorna um tipoOptionque representa como atualizar a structoptions.
type options struct {
port *int
}
type Option func(options *options) error
func WithPort(port int) Option {
return func(options *options) error {
if port < 0 {
return errors.New("port should be positive")
}
options.port = &port
return nil
}
}
func NewServer(addr string, opts ...Option) ( *http.Server, error) {
var options options
for _, opt := range opts {
err := opt(&options)
if err != nil {
return nil, err
}
}
// At this stage, the options struct is built and contains the config
// Therefore, we can implement our logic related to port configuration
var port int
if options.port == nil {
port = defaultHTTPPort
} else {
if *options.port == 0 {
port = randomPort()
} else {
port = *options.port
}
}
// ...
}
O padrão de opções funcionais fornece uma maneira prática e amigável à API de lidar com opções. Embora o padrão do construtor possa ser uma opção válida, ele tem algumas desvantagens menores (ter que passar uma estrutura de configuração que pode estar vazia ou uma maneira menos prática de lidar com o gerenciamento de erros) que tendem a tornar o padrão de opções funcionais a maneira idiomática de lidar com esse tipo de problema no Go.
Desorganização do projeto (estrutura do projeto e organização do pacote) (#12)
No que diz respeito à organização geral, existem diferentes escolas de pensamento. Por exemplo, devemos organizar a nossa aplicação por contexto ou por camada? Depende de nossas preferências. Podemos preferir agrupar o código por contexto (como o contexto do cliente, o contexto do contrato, etc.), ou podemos preferir seguir os princípios da arquitetura hexagonal e agrupar por camada técnica. Se a decisão que tomarmos se adequar ao nosso caso de uso, não pode ser uma decisão errada, desde que permaneçamos consistentes com ela.
Em relação aos pacotes, existem várias práticas recomendadas que devemos seguir. Primeiro, devemos evitar pacotes prematuros porque podem complicar demais um projeto. Às vezes, é melhor usar uma organização simples e fazer nosso projeto evoluir quando entendemos o que ele contém, em vez de nos forçarmos a fazer a estrutura perfeita desde o início. A granularidade é outra coisa essencial a considerar. Devemos evitar dezenas de pacotes nano contendo apenas um ou dois arquivos. Se o fizermos, é porque provavelmente perdemos algumas conexões lógicas entre esses pacotes, tornando nosso projeto mais difícil de ser compreendido pelos leitores. Por outro lado, também devemos evitar pacotes grandes que diluem o significado do nome de um pacote.
A nomenclatura dos pacotes também deve ser considerada com cuidado. Como todos sabemos (como desenvolvedores), nomear é difícil. Para ajudar os clientes a entender um projeto Go, devemos nomear nossos pacotes de acordo com o que eles fornecem, não com o que contêm. Além disso, a nomenclatura deve ser significativa. Portanto, o nome de um pacote deve ser curto, conciso, expressivo e, por convenção, uma única palavra minúscula.
Quanto ao que exportar, a regra é bastante simples. Devemos minimizar o que deve ser exportado tanto quanto possível para reduzir o acoplamento entre pacotes e manter ocultos os elementos exportados desnecessários. Se não tivermos certeza se devemos ou não exportar um elemento, devemos optar por não exportá-lo. Mais tarde, se descobrirmos que precisamos exportá-lo, poderemos ajustar nosso código. Vamos também ter em mente algumas exceções, como fazer com que os campos sejam exportados para que uma estrutura possa ser desempacotada com encoding/json.
Organizar um projeto não é simples, mas seguir essas regras deve ajudar a facilitar sua manutenção. No entanto, lembre-se de que a consistência também é vital para facilitar a manutenção. Portanto, vamos nos certificar de manter as coisas o mais consistentes possível dentro de uma base de código.
Note
Em 2023, a equipe Go publicou uma diretriz oficial para organizar/estruturar um projeto Go: go.dev/doc/modules/layout
Criando pacotes de utilitários (#13)
TL;DR
A nomenclatura é uma parte crítica do design do aplicativo. Criar pacotes como common, util e shared não traz muito valor para o leitor. Refatore esses pacotes em nomes de pacotes significativos e específicos.
Além disso, tenha em mente que nomear um pacote com base no que ele fornece e não no que ele contém pode ser uma forma eficiente de aumentar sua expressividade.
Ignorando colisões de nomes de pacotes (#14)
TL;DR
Para evitar colisões de nomes entre variáveis e pacotes, levando a confusão ou talvez até bugs, use nomes exclusivos para cada um. Se isso não for viável, use um alias de importação para alterar o qualificador para diferenciar o nome do pacote do nome da variável ou pense em um nome melhor.
As colisões de pacotes ocorrem quando um nome de variável colide com um nome de pacote existente, impedindo que o pacote seja reutilizado. Devemos evitar colisões de nomes de variáveis para evitar ambiguidade. Se enfrentarmos uma colisão, devemos encontrar outro nome significativo ou usar um alias de importação.
Documentação de código ausente (#15)
TL;DR
Para ajudar clientes e mantenedores a entender a finalidade do seu código, documente os elementos exportados.
A documentação é um aspecto importante da programação. Simplifica como os clientes podem consumir uma API, mas também pode ajudar na manutenção de um projeto. No Go, devemos seguir algumas regras para tornar nosso código idiomático:
Primeiro, cada elemento exportado deve ser documentado. Seja uma estrutura, uma interface, uma função ou qualquer outra coisa, se for exportado deve ser documentado. A convenção é adicionar comentários, começando com o nome do elemento exportado.
Por convenção, cada comentário deve ser uma frase completa que termina com pontuação. Tenha também em mente que quando documentamos uma função (ou um método), devemos destacar o que a função pretende fazer, não como o faz; isso pertence ao núcleo de uma função e comentários, não à documentação. Além disso, o ideal é que a documentação forneça informações suficientes para que o consumidor não precise olhar nosso código para entender como usar um elemento exportado.
Quando se trata de documentar uma variável ou constante, podemos estar interessados em transmitir dois aspectos: sua finalidade e seu conteúdo. O primeiro deve funcionar como documentação de código para ser útil para clientes externos. Este último, porém, não deveria ser necessariamente público.
Para ajudar clientes e mantenedores a entender o escopo de um pacote, devemos também documentar cada pacote. A convenção é iniciar o comentário com // Package seguido do nome do pacote. A primeira linha de um comentário de pacote deve ser concisa. Isso porque ele aparecerá no pacote. Então, podemos fornecer todas as informações que precisamos nas linhas seguintes.
Documentar nosso código não deve ser uma restrição. Devemos aproveitar a oportunidade para garantir que isso ajude os clientes e mantenedores a entender o propósito do nosso código.
Não usando linters (#16)
TL;DR
Para melhorar a qualidade e consistência do código, use linters e formatadores.
Um linter é uma ferramenta automática para analisar código e detectar erros. O escopo desta seção não é fornecer uma lista exaustiva dos linters existentes; caso contrário, ele ficará obsoleto rapidamente. Mas devemos entender e lembrar por que os linters são essenciais para a maioria dos projetos Go.
No entanto, se você não é um usuário regular de linters, aqui está uma lista que você pode usar diariamente:
- https://golang.org/cmd/vet—A standard Go analyzer
- https://github.com/kisielk/errcheck—An error checker
- https://github.com/fzipp/gocyclo—A cyclomatic complexity analyzer
- https://github.com/jgautheron/goconst—A repeated string constants analyzer
Além dos linters, também devemos usar formatadores de código para corrigir o estilo do código. Aqui está uma lista de alguns formatadores de código para você experimentar:
- https://golang.org/cmd/gofmt—A standard Go code formatter
- https://godoc.org/golang.org/x/tools/cmd/goimports—A standard Go imports formatter
Enquanto isso, devemos também dar uma olhada em golangci-lint (https://github.com/golangci/golangci-lint). É uma ferramenta de linting que fornece uma fachada sobre muitos linters e formatadores úteis. Além disso, permite executar os linters em paralelo para melhorar a velocidade de análise, o que é bastante útil.
Linters e formatadores são uma forma poderosa de melhorar a qualidade e consistência de nossa base de código. Vamos dedicar um tempo para entender qual deles devemos usar e garantir que automatizamos sua execução (como um precommit hook de CI ou Git).
Tipos de dados
Criando confusão com literais octais (#17)
TL;DR
Ao ler o código existente, lembre-se de que literais inteiros começando com 0 são números octais. Além disso, para melhorar a legibilidade, torne os inteiros octais explícitos prefixando-os com 0o.
Os números octais começam com 0 (por exemplo, 010 é igual a 8 na base 10). Para melhorar a legibilidade e evitar possíveis erros para futuros leitores de código, devemos tornar os números octais explícitos usando o prefixo 0o (por exemplo, 0o10).
Devemos também observar as outras representações literais inteiras:
- Binário—Usa um prefixo
0bou0B(por exemplo,0b100é igual a 4 na base 10) - Hexadecimal—Usa um prefixo
0xou0X(por exemplo,0xFé igual a 15 na base 10) - Imaginário—Usa um
isufixo (por exemplo,3i)
Também podemos usar um caractere de sublinhado (_) como separador para facilitar a leitura. Por exemplo, podemos escrever 1 bilhão desta forma: 1_000_000_000. Também podemos usar o caractere sublinhado com outras representações (por exemplo, 0b00_00_01).
Negligenciando estouros de número inteiro (#18)
TL;DR
Como os overflows e underflows de números inteiros são tratados silenciosamente no Go, você pode implementar suas próprias funções para capturá-los.
No Go, um estouro de número inteiro que pode ser detectado em tempo de compilação gera um erro de compilação. Por exemplo,
No entanto, em tempo de execução, um overflow ou underflow de inteiro é silencioso; isso não leva ao pânico do aplicativo. É essencial ter esse comportamento em mente, pois ele pode levar a bugs sorrateiros (por exemplo, um incremento de número inteiro ou adição de números inteiros positivos que leva a um resultado negativo).
Não entendendo os pontos flutuantes (#19)
TL;DR
Fazer comparações de ponto flutuante dentro de um determinado delta pode garantir que seu código seja portátil. Ao realizar adição ou subtração, agrupe as operações com ordem de grandeza semelhante para favorecer a precisão. Além disso, execute multiplicação e divisão antes da adição e subtração.
Em Go, existem dois tipos de ponto flutuante (se omitirmos os números imaginários): float32 e float64. O conceito de ponto flutuante foi inventado para resolver o principal problema dos números inteiros: sua incapacidade de representar valores fracionários. Para evitar surpresas desagradáveis, precisamos saber que a aritmética de ponto flutuante é uma aproximação da aritmética real.
Para isso, veremos um exemplo de multiplicação:
Podemos esperar que este código imprima o resultado de 1.0001 * 1.0001 = 1,00020001, certo? No entanto, executá-lo na maioria dos processadores x86 imprime 1.0002.
Como os tipos float32 e float64 em Go são aproximações, temos que ter algumas regras em mente:
- Ao comparar dois números de ponto flutuante, verifique se a diferença está dentro de um intervalo aceitável.
- Ao realizar adições ou subtrações, agrupe operações com ordem de magnitude semelhante para melhor precisão.
- Para favorecer a precisão, se uma sequência de operações exigir adição, subtração, multiplicação ou divisão, execute primeiro as operações de multiplicação e divisão.
Não entendendo o comprimento e a capacidade de slice (#20)
TL;DR
Compreender a diferença entre comprimento e capacidade da slice deve fazer parte do conhecimento básico de um desenvolvedor Go. O comprimento de slice é o número de elementos disponíveis na slice, enquanto a capacidade de slice é o número de elementos na matriz de apoio.
Leia a seção completa aqui.
Inicialização de slice ineficiente (#21)
TL;DR
Ao criar uma fatia, inicialize-a com um determinado comprimento ou capacidade se o seu comprimento já for conhecido. Isso reduz o número de alocações e melhora o desempenho.
Ao inicializar uma fatia usando make, podemos fornecer um comprimento e uma capacidade opcional. Esquecer de passar um valor apropriado para ambos os parâmetros quando faz sentido é um erro generalizado. Na verdade, isso pode levar a múltiplas cópias e esforço adicional para o GC limpar as matrizes de apoio temporárias. Em termos de desempenho, não há uma boa razão para não ajudar o tempo de execução do Go.
Nossas opções são alocar uma fatia com determinada capacidade ou comprimento. Destas duas soluções, vimos que a segunda tende a ser um pouco mais rápida. Mas usar uma determinada capacidade e anexar pode ser mais fácil de implementar e ler em alguns contextos.
Estar confuso sobre slice nula vs. slice vazia (#22)
TL;DR
To prevent common confusions such as when using the encoding/json or the reflect package, you need to understand the difference between nil and empty slices. Both are zero-length, zero-capacity slices, but only a nil slice doesn’t require allocation.
No Go, há uma distinção entre slices nulas e vazias. Uma slice nula é igual a nil, enquanto uma slice vazia tem comprimento zero. Uma slice nula está vazia, mas uma slice vazia não é necessariamente nil. Enquanto isso, uma slice nula não requer nenhuma alocação. Vimos ao longo desta seção como inicializar uma slice dependendo do contexto usando
var s []stringse não tivermos certeza sobre o comprimento final e a fatia pode estar vazia[]string(nil)como açúcar sintático para criar uma fatia nula e vaziamake([]string, length)se o comprimento futuro for conhecido
A última opção, []string{} deve ser evitada se inicializarmos a fatia sem elementos. Finalmente, vamos verificar se as bibliotecas que usamos fazem distinções entre fatias nulas e vazias para evitar comportamentos inesperados.
Não verificar corretamente se um slice está vazio (#23)
TL;DR
Para verificar se uma fatia não contém nenhum elemento, verifique seu comprimento. Esta verificação funciona independentemente de o slice estar nil ou vazio. O mesmo vale para maps. Para projetar APIs inequívocas, você não deve distinguir entre slice nulos e vazios.
Para determinar se um slice possui elementos, podemos fazê-lo verificando se o slice é nulo ou se seu comprimento é igual a 0. Verificar o comprimento é a melhor opção a seguir, pois cobrirá ambos se o slice estiver vazio ou se o slice é nulo.
Enquanto isso, ao projetar interfaces, devemos evitar distinguir slices nulos e vazios, o que leva a erros sutis de programação. Ao retornar slices, não deve haver diferença semântica nem técnica se retornarmos um slice nulo ou vazio. Ambos devem significar a mesma coisa para quem liga. Este princípio é o mesmo com maps. Para verificar se um map está vazio, verifique seu comprimento, não se é nulo.
Não fazer cópias de slcies corretamente (#24)
TL;DR
Para copiar um slice para outro usando a função copy, lembre-se que o número de elementos copiados corresponde ao mínimo entre os comprimentos dos dois slices.
Copiar elementos de um slice para outro é uma operação razoavelmente frequente. Ao utilizar a cópia, devemos lembrar que o número de elementos copiados para o destino corresponde ao mínimo entre os comprimentos dos dois slices. Tenha também em mente que existem outras alternativas para copiar um slice, por isso não devemos nos surpreender se as encontrarmos em uma base de código.
Efeitos colaterais inesperados usando o slice append (#25)
TL;DR
Usar copy ou a expressão de slice completa é uma forma de evitar que append crie conflitos se duas funções diferentes usarem slices apoiados pela mesmo array. No entanto, apenas uma cópia de slice evita vazamentos de memória se você quiser reduzir um slice grande.
Ao usar o slicing, devemos lembrar que podemos enfrentar uma situação que leva a efeitos colaterais não intencionais. Se o slice resultante tiver um comprimento menor que sua capacidade, o acréscimo poderá alterar o slice original. Se quisermos restringir a gama de possíveis efeitos colaterais, podemos usar uma cópia de slice ou a expressão de slice completa, o que nos impede de fazer uma cópia.
Note
s[low:high:max](expressão de slice completo): Esta instrução cria um slice semelhante àquele criado com s[low:high], exceto que a capacidade de slice resultante é igual a max - low.
Slices e vazamentos de memória (#26)
TL;DR
Trabalhando com um slice de ponteiros ou estruturas com campos de ponteiro, você pode evitar vazamentos de memória marcando como nulos os elementos excluídos por uma operação de fatiamento.
Vazamento de capacidade
Lembre-se de que fatiar um slice ou array grande pode levar a um potencial alto consumo de memória. O espaço restante não será recuperado pelo GC e podemos manter um grande array de apoio, apesar de usarmos apenas alguns elementos. Usar uma cópia em slice é a solução para evitar tal caso.
Slice e ponteiros
Quando usamos a operação de fatiamento com ponteiros ou estruturas com campos de ponteiro, precisamos saber que o GC não recuperará esses elementos. Nesse caso, as duas opções são realizar uma cópia ou marcar explicitamente os elementos restantes ou seus campos como nil.
Inicialização ineficiente do mapa (#27)
TL;DR
Ao criar um mapa, inicialize-o com um determinado comprimento se o seu comprimento já for conhecido. Isso reduz o número de alocações e melhora o desempenho.
Um mapa fornece uma coleção não ordenada de pares chave-valor em que todas as chaves são distintas. No Go, um mapa é baseado na estrutura de dados da tabela hash. Internamente, uma tabela hash é uma matriz de intervalos e cada intervalo é um ponteiro para uma matriz de pares de valores-chave.
Se soubermos de antemão o número de elementos que um mapa conterá, devemos criá-lo fornecendo um tamanho inicial. Fazer isso evita o crescimento potencial do mapa, o que é bastante pesado em termos de computação porque requer a realocação de espaço suficiente e o reequilíbrio de todos os elementos.
Mapas e vazamentos de memória (#28)
TL;DR
Um mapa sempre pode crescer na memória, mas nunca diminui. Portanto, se isso causar alguns problemas de memória, você pode tentar diferentes opções, como forçar Go a recriar o mapa ou usar ponteiros.
Leia a seção completa aqui.
Comparando valores incorretamente (#29)
TL;DR
Para comparar tipos em Go, você pode usar os operadores == e != se dois tipos forem comparáveis: booleanos, numerais, strings, ponteiros, canais e estruturas são compostos inteiramente de tipos comparáveis. Caso contrário, você pode usar reflect.DeepEquale pagar o preço da reflexão ou usar implementações e bibliotecas personalizadas.
É essencial entender como usar == e != para fazer comparações de forma eficaz. Podemos usar esses operadores em operandos comparáveis:
- Booleans—Compara se dois booleanos são iguais.
- Numerics (int, float, and complex types)—Compare se dois números são iguais.
- Strings—Compare se duas strings são iguais.
- Channels—Compare se dois canais foram criados pela mesma chamada a ser feita ou se ambos são nulos.
- Interfaces—Compare se duas interfaces têm tipos dinâmicos idênticos e valores dinâmicos iguais ou se ambas são nulas.
- Pointers—Compare se dois ponteiros apontam para o mesmo valor na memória ou se ambos são nulos.
- Structs and arrays—Compare se são compostas de tipos semelhantes.
Note
Também podemos usar os operadores ?, >=, < e > com tipos numéricos para comparar valores e com strings para comparar sua ordem lexical.
Se os operandos não forem comparáveis (por exemplo, slices e mapas), teremos que usar outras opções, como reflexão. A reflexão é uma forma de metaprogramação e se refere à capacidade de um aplicativo de introspectar e modificar sua estrutura e comportamento. Por exemplo, em Go, podemos usar reflect.DeepEqual. Esta função informa se dois elementos são profundamente iguais percorrendo recursivamente dois valores. Os elementos que ele aceita são tipos básicos mais arrays, estruturas, slices, mapas, ponteiros, interfaces e funções. No entanto, o principal problema é a penalidade de desempenho.
Se o desempenho for crucial em tempo de execução, implementar nosso método customizado pode ser a melhor solução. Uma observação adicional: devemos lembrar que a biblioteca padrão possui alguns métodos de comparação existentes. Por exemplo, podemos usar a função bytes.Compare otimizada para comparar duas slices de bytes. Antes de implementar um método customizado, precisamos ter certeza de não reinventar a roda.
Estruturas de Controle
Ignorando que os elementos são copiados em loops de range (#30)
TL;DR
O elemento de valor em um loop de range é uma cópia. Portanto, para modificar uma struct, por exemplo, acesse-a através de seu índice ou através de um loop for clássico (a menos que o elemento ou campo que você deseja modificar seja um ponteiro).
Um range loop permite iterar em diferentes estruturas de dados:
- String
- Array
- Pointer to an array
- Slice
- Map
- Receiving channel
Comparado a um for loop clássico, um loop range é uma maneira conveniente de iterar todos os elementos de uma dessas estruturas de dados, graças à sua sintaxe concisa.
Ainda assim, devemos lembrar que o elemento de valor em um range loop é uma cópia. Portanto, se o valor for uma estrutura que precisamos sofrer mutação, atualizaremos apenas a cópia, não o elemento em si, a menos que o valor ou campo que modificamos seja um ponteiro. As opções preferidas são acessar o elemento através do índice usando um range loop ou um loop for clássico.
Ignorando como os argumentos são avaliados em range loops (canais e arrays) (#31)
TL;DR
Entender que a expressão passada ao operador range é avaliada apenas uma vez antes do início do loop pode ajudar a evitar erros comuns, como atribuição ineficiente em canal ou iteração de slice.
O range loop avalia a expressão fornecida apenas uma vez, antes do início do loop, fazendo uma cópia (independentemente do tipo). Devemos lembrar deste comportamento para evitar erros comuns que podem, por exemplo, nos levar a acessar o elemento errado. Por exemplo:
Este código atualiza o último índice para 10. No entanto, se executarmos este código, ele não imprimirá 10; imprime 2.
 Ignorando os impactos do uso de elementos ponteiros em
Ignorando os impactos do uso de elementos ponteiros em range loops (#32)
Warning
Este erro não é mais relevante no Go 1.22 (detalhes).
Fazendo suposições erradas durante as iterações de maps (ordenação e inserção do mapa durante a iteração) (#33)
TL;DR
Para garantir resultados previsíveis ao usar maps, lembre-se de que uma estrutura de dados de mapa:
- Não ordena os dados por chaves
- Não preserva o pedido de inserção
- Não tem uma ordem de iteração determinística
- Não garante que um elemento adicionado durante uma iteração será produzido durante esta iteração
Ignorando como a declaração break funciona (#34)
TL;DR
Usar break ou continue com um rótulo impõe a quebra de uma instrução específica. Isso pode ser útil com instruções switch ou select dentro de loops.
Uma instrução break é comumente usada para encerrar a execução de um loop. Quando loops são usados em conjunto com switch ou select, os desenvolvedores frequentemente cometem o erro de quebrar a instrução errada. Por exemplo:
A instrução break não encerra o loop for: em vez disso, ela encerra a instrução switch. Portanto, em vez de iterar de 0 a 2, este código itera de 0 a 4: 0 1 2 3 4.
Uma regra essencial a ter em mente é que uma instrução break encerra a execução da instrução for, switch, ou mais interna select. No exemplo anterior, ele encerra a instrução switch.
Para quebrar o loop em vez da instrução switch, a maneira mais idiomática é usar um rótulo:
Aqui, associamos o looprótulo ao for loop. Então, como fornecemos o loop rótulo para a instrução break, ela interrompe o loop, não a opção. Portanto, esta nova versão será impressa 0 1 2, como esperávamos.
Usando defer dentro de um loop (#35)
TL;DR
Extrair a lógica do loop dentro de uma função leva à execução de uma instrução defer no final de cada iteração.
A instrução defer atrasa a execução de uma chamada até que a função circundante retorne. É usado principalmente para reduzir o código padrão. Por exemplo, se um recurso precisar ser fechado eventualmente, podemos usar defer para evitar a repetição das chamadas de fechamento antes de cada return.
Um erro comum com defer é esquecer que ele agenda uma chamada de função quando a função circundante retorna. Por exemplo:
func readFiles(ch <-chan string) error {
for path := range ch {
file, err := os.Open(path)
if err != nil {
return err
}
defer file.Close()
// Do something with file
}
return nil
}
As chamadas defer não são executadas durante cada iteração do loop, mas quando a função readFiles retorna. Se readFiles não retornar, os descritores de arquivos ficarão abertos para sempre, causando vazamentos.
Uma opção comum para corrigir esse problema é criar uma função circundante após defer, chamada durante cada iteração:
func readFiles(ch <-chan string) error {
for path := range ch {
if err := readFile(path); err != nil {
return err
}
}
return nil
}
func readFile(path string) error {
file, err := os.Open(path)
if err != nil {
return err
}
defer file.Close()
// Do something with file
return nil
}
Outra solução é tornar a função readFile um encerramento, mas intrinsecamente, esta permanece a mesma solução: adicionar outra função circundante para executar as chamadas defer durante cada iteração.
Strings
Não entendendo o conceito de rune (#36)
TL;DR
Entender que uma runa corresponde ao conceito de um ponto de código Unicode e que pode ser composta de múltiplos bytes deve fazer parte do conhecimento básico do desenvolvedor Go para trabalhar com precisão com strings.
Como as runas estão por toda parte no Go, é importante entender o seguinte:
- Um conjunto de caracteres é um conjunto de caracteres, enquanto uma codificação descreve como traduzir um conjunto de caracteres em binário.
- No Go, uma string faz referência a uma fatia imutável de bytes arbitrários.
- O código-fonte Go é codificado usando UTF-8. Portanto, todos os literais de string são strings UTF-8. Mas como uma string pode conter bytes arbitrários, se for obtida de outro lugar (não do código-fonte), não há garantia de que seja baseada na codificação UTF-8.
- A
runecorresponde ao conceito de ponto de código Unicode, significando um item representado por um único valor. - Usando UTF-8, um ponto de código Unicode pode ser codificado em 1 a 4 bytes.
- Usar
len()na string em Go retorna o número de bytes, não o número de runas.
Iteração de string imprecisa (#37)
TL;DR
Iterar em uma string com o operador range itera nas runas com o índice correspondente ao índice inicial da sequência de bytes da runa. Para acessar um índice de runa específico (como a terceira runa), converta a string em um arquivo []rune.
Iterar em uma string é uma operação comum para desenvolvedores. Talvez queiramos realizar uma operação para cada runa na string ou implementar uma função personalizada para procurar uma substring específica. Em ambos os casos, temos que iterar nas diferentes runas de uma string. Mas é fácil ficar confuso sobre como funciona a iteração.
For example, consider the following example:
s := "hêllo"
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
Vamos destacar três pontos que podem ser confusos:
- A segunda runa é Ã na saída em vez de ê.
- Saltamos da posição 1 para a posição 3: o que há na posição 2?
- len retorna uma contagem de 6, enquanto s contém apenas 5 runas.
Vamos começar com a última observação. Já mencionamos que len retorna o número de bytes em uma string, não o número de runas. Como atribuímos uma string literal a s, s é uma string UTF-8. Enquanto isso, o caractere especial “ê” não é codificado em um único byte; requer 2 bytes. Portanto, chamar len(s) retorna 6.
Enquanto isso, no exemplo anterior, temos que entender que não repetimos cada runa; em vez disso, iteramos sobre cada índice inicial de uma runa:
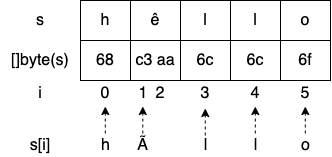
Imprimir s[i] não imprime a i-ésima runa; imprime a representação UTF-8 do byte em index i. Portanto, imprimimos "hÃllo" em vez de "hêllo".
Se quisermos imprimir todas as diferentes runas, podemos usar o elemento value do operador range:
Ou podemos converter a string em uma fatia de runas e iterar sobre ela:
Observe que esta solução introduz uma sobrecarga de tempo de execução em comparação com a anterior. Na verdade, converter uma string em uma fatia de runas requer a alocação de uma fatia adicional e a conversão dos bytes em runas: uma complexidade de tempo O(n) com n o número de bytes na string. Portanto, se quisermos iterar todas as runas, devemos usar a primeira solução.
Porém, se quisermos acessar a i-ésima runa de uma string com a primeira opção, não teremos acesso ao índice da runa; em vez disso, conhecemos o índice inicial de uma runa na sequência de bytes.
Uso indevido de funções de trim (#38)
TL;DR
strings.TrimRight/strings.TrimLeft remove todas as runas finais/iniciais contidas em um determinado conjunto, enquanto strings.TrimSuffix/strings.TrimPrefix retorna uma string sem um sufixo/prefixo fornecido.
Por exemplo:
O exemplo imprime 123:

Por outro lado, strings.TrimLeft remove todas as runas principais contidas em um conjunto.
Por outro lado, strings.TrimSuffix/strings.TrimPrefix retorna uma string sem o sufixo/prefixo final fornecido.
Concatenação de strings subotimizada (#39)
TL;DR
A concatenação de uma lista de strings deve ser feita com strings.Builder para evitar a alocação de uma nova string durante cada iteração.
Vamos considerar uma função concat que concatena todos os elementos string de uma fatia usando o operador +=:
func concat(values []string) string {
s := ""
for _, value := range values {
s += value
}
return s
}
Durante cada iteração, o operador += concatena com s a sequência de valores. À primeira vista, esta função pode não parecer errada. Mas com esta implementação, esquecemos uma das principais características de uma string: a sua imutabilidade. Portanto, cada iteração não é atualizada s; ele realoca uma nova string na memória, o que impacta significativamente o desempenho desta função.
Felizmente, existe uma solução para lidar com esse problema, usando strings.Builder:
func concat(values []string) string {
sb := strings.Builder{}
for _, value := range values {
_, _ = sb.WriteString(value)
}
return sb.String()
}
Durante cada iteração, construímos a string resultante chamando o método WriteString que anexa o conteúdo do valor ao seu buffer interno, minimizando assim a cópia da memória.
Note
WriteString retorna um erro como segunda saída, mas nós o ignoramos propositalmente. Na verdade, este método nunca retornará um erro diferente de zero. Então, qual é o propósito deste método retornar um erro como parte de sua assinatura? strings.Builder implementa a io.StringWriter interface, que contém um único método: WriteString(s string) (n int, err error). Portanto, para estar em conformidade com esta interface, WriteString deve retornar um erro.
Internamente, strings.Builder contém uma fatia de bytes. Cada chamada para WriteString resulta em uma chamada para anexar nesta fatia. Existem dois impactos. Primeiro, esta estrutura não deve ser usada simultaneamente, pois as chamadas append levariam a condições de corrida. O segundo impacto é algo que vimos no mistake #21, "Inicialização de slice ineficiente": se o comprimento futuro de uma slice já for conhecido, devemos pré-alocá-la. Para isso, strings.Builder expõe um método Grow(n int) para garantir espaço para outros n bytes:
func concat(values []string) string {
total := 0
for i := 0; i < len(values); i++ {
total += len(values[i])
}
sb := strings.Builder{}
sb.Grow(total) (2)
for _, value := range values {
_, _ = sb.WriteString(value)
}
return sb.String()
}
Vamos executar um benchmark para comparar as três versões (v1 usando +=; v2 usando strings.Builder{} sem pré-alocação; e v3 usando strings.Builder{} com pré-alocação). A slice de entrada contém 1.000 strings e cada string contém 1.000 bytes:
BenchmarkConcatV1-4 16 72291485 ns/op
BenchmarkConcatV2-4 1188 878962 ns/op
BenchmarkConcatV3-4 5922 190340 ns/op
Como podemos ver, a versão mais recente é de longe a mais eficiente: 99% mais rápida que a v1 e 78% mais rápida que a v2.
strings.Builder é a solução recomendada para concatenar uma lista de strings. Normalmente, esta solução deve ser usada dentro de um loop. Na verdade, se precisarmos apenas concatenar algumas strings (como um nome e um sobrenome), o uso strings.Builder não é recomendado, pois isso tornará o código um pouco menos legível do que usar o operador += or fmt.Sprintf.
Conversões de string inúteis (#40)
TL;DR
Lembrar que o pacote bytes oferece as mesmas operações que o pacote strings pode ajudar a evitar conversões extras de bytes/string.
Ao optar por trabalhar com uma string ou um []byte, a maioria dos programadores tende a preferir strings por conveniência. Mas a maior parte da E/S é realmente feita com []byte. Por exemplo, io.Reader, io.Writer e io.ReadAll trabalham com []byte, não com strings.
Quando nos perguntamos se devemos trabalhar com strings ou []byte, lembremos que trabalhar com []bytenão é necessariamente menos conveniente. Na verdade, todas as funções exportadas do pacote strings também possuem alternativas no pacote bytes: Split, Count, Contains, Index e assim por diante. Portanto, estejamos fazendo I/O ou não, devemos primeiro verificar se poderíamos implementar um fluxo de trabalho completo usando bytes em vez de strings e evitar o preço de conversões adicionais.
Vazamentos de substring e memória (#41)
TL;DR
Usar cópias em vez de substrings pode evitar vazamentos de memória, pois a string retornada por uma operação de substring será apoiada pela mesma matriz de bytes.
In mistake #26, “Slices and memory leaks,” we saw how slicing a slice or array may lead to memory leak situations. This principle also applies to string and substring operations.
We need to keep two things in mind while using the substring operation in Go. First, the interval provided is based on the number of bytes, not the number of runes. Second, a substring operation may lead to a memory leak as the resulting substring will share the same backing array as the initial string. The solutions to prevent this case from happening are to perform a string copy manually or to use strings.Clone from Go 1.18.
Functions and Methods
Não saber que tipo de receptor usar (#42)
TL;DR
A decisão de usar um valor ou um receptor de ponteiro deve ser tomada com base em fatores como o tipo, se deve sofrer mutação, se contém um campo que não pode ser copiado e o tamanho do objeto. Em caso de dúvida, use um receptor de ponteiro.
Choosing between value and pointer receivers isn’t always straightforward. Let’s discuss some of the conditions to help us choose.
A receiver must be a pointer
- If the method needs to mutate the receiver. This rule is also valid if the receiver is a slice and a method needs to append elements:
- If the method receiver contains a field that cannot be copied: for example, a type part of the sync package (see #74, “Copying a sync type”).
A receiver should be a pointer
- If the receiver is a large object. Using a pointer can make the call more efficient, as doing so prevents making an extensive copy. When in doubt about how large is large, benchmarking can be the solution; it’s pretty much impossible to state a specific size, because it depends on many factors.
A receiver must be a value
- If we have to enforce a receiver’s immutability.
- If the receiver is a map, function, or channel. Otherwise, a compilation error occurs.
A receiver should be a value
- If the receiver is a slice that doesn’t have to be mutated.
- If the receiver is a small array or struct that is naturally a value type without mutable fields, such as
time.Time. - If the receiver is a basic type such as
int,float64, orstring.
Of course, it’s impossible to be exhaustive, as there will always be edge cases, but this section’s goal was to provide guidance to cover most cases. By default, we can choose to go with a value receiver unless there’s a good reason not to do so. In doubt, we should use a pointer receiver.
Nunca usando parâmetros de resultado nomeados (#43)
TL;DR
Usar parâmetros de resultado nomeados pode ser uma maneira eficiente de melhorar a legibilidade de uma função/método, especialmente se vários parâmetros de resultado tiverem o mesmo tipo. Em alguns casos, esta abordagem também pode ser conveniente porque os parâmetros de resultado nomeados são inicializados com seu valor zero. Mas tenha cuidado com os possíveis efeitos colaterais.
When we return parameters in a function or a method, we can attach names to these parameters and use them as regular variables. When a result parameter is named, it’s initialized to its zero value when the function/method begins. With named result parameters, we can also call a naked return statement (without arguments). In that case, the current values of the result parameters are used as the returned values.
Here’s an example that uses a named result parameter b:
In this example, we attach a name to the result parameter: b. When we call return without arguments, it returns the current value of b.
In some cases, named result parameters can also increase readability: for example, if two parameters have the same type. In other cases, they can also be used for convenience. Therefore, we should use named result parameters sparingly when there’s a clear benefit.
Efeitos colaterais não intencionais com parâmetros de resultado nomeados (#44)
TL;DR
Consulte #43.
We mentioned why named result parameters can be useful in some situations. But as these result parameters are initialized to their zero value, using them can sometimes lead to subtle bugs if we’re not careful enough. For example, can you spot what’s wrong with this code?
func (l loc) getCoordinates(ctx context.Context, address string) (
lat, lng float32, err error) {
isValid := l.validateAddress(address) (1)
if !isValid {
return 0, 0, errors.New("invalid address")
}
if ctx.Err() != nil { (2)
return 0, 0, err
}
// Get and return coordinates
}
The error might not be obvious at first glance. Here, the error returned in the if ctx.Err() != nil scope is err. But we haven’t assigned any value to the err variable. It’s still assigned to the zero value of an error type: nil. Hence, this code will always return a nil error.
When using named result parameters, we must recall that each parameter is initialized to its zero value. As we have seen in this section, this can lead to subtle bugs that aren’t always straightforward to spot while reading code. Therefore, let’s remain cautious when using named result parameters, to avoid potential side effects.
Retornando um receptor nulo (#45)
TL;DR
Ao retornar uma interface, tenha cuidado para não retornar um ponteiro nulo, mas um valor nulo explícito. Caso contrário, poderão ocorrer consequências não intencionais e o chamador receberá um valor diferente de zero.
Usando um nome de arquivo como entrada de função (#46)
TL;DR
Projetar funções para receber tipos io.Reader em vez de nomes de arquivos melhora a capacidade de reutilização de uma função e facilita o teste.
Accepting a filename as a function input to read from a file should, in most cases, be considered a code smell (except in specific functions such as os.Open). Indeed, it makes unit tests more complex because we may have to create multiple files. It also reduces the reusability of a function (although not all functions are meant to be reused). Using the io.Reader interface abstracts the data source. Regardless of whether the input is a file, a string, an HTTP request, or a gRPC request, the implementation can be reused and easily tested.
Ignorando como argumentos defer e receptores são avaliados (avaliação de argumentos, ponteiros e receptores de valor) (#47)
TL;DR
Passar um ponteiro para uma função defer e agrupar uma chamada dentro de um closure são duas soluções possíveis para superar a avaliação imediata de argumentos e receptores.
In a defer function the arguments are evaluated right away, not once the surrounding function returns. For example, in this code, we always call notify and incrementCounter with the same status: an empty string.
const (
StatusSuccess = "success"
StatusErrorFoo = "error_foo"
StatusErrorBar = "error_bar"
)
func f() error {
var status string
defer notify(status)
defer incrementCounter(status)
if err := foo(); err != nil {
status = StatusErrorFoo
return err
}
if err := bar(); err != nil {
status = StatusErrorBar
return err
}
status = StatusSuccess <5>
return nil
}
Indeed, we call notify(status) and incrementCounter(status) as defer functions. Therefore, Go will delay these calls to be executed once f returns with the current value of status at the stage we used defer, hence passing an empty string.
Two leading options if we want to keep using defer.
The first solution is to pass a string pointer:
func f() error {
var status string
defer notify(&status)
defer incrementCounter(&status)
// The rest of the function unchanged
}
Using defer evaluates the arguments right away: here, the address of status. Yes, status itself is modified throughout the function, but its address remains constant, regardless of the assignments. Hence, if notify or incrementCounter uses the value referenced by the string pointer, it will work as expected. But this solution requires changing the signature of the two functions, which may not always be possible.
There’s another solution: calling a closure (an anonymous function value that references variables from outside its body) as a defer statement:
func f() error {
var status string
defer func() {
notify(status)
incrementCounter(status)
}()
// The rest of the function unchanged
}
Here, we wrap the calls to both notify and incrementCounter within a closure. This closure references the status variable from outside its body. Therefore, status is evaluated once the closure is executed, not when we call defer. This solution also works and doesn’t require notify and incrementCounter to change their signature.
Let's also note this behavior applies with method receiver: the receiver is evaluated immediately.
Error Management
Pânico (#48)
TL;DR
Usar panic é uma opção para lidar com erros no Go. No entanto, só deve ser usado com moderação em condições irrecuperáveis: por exemplo, para sinalizar um erro do programador ou quando você não consegue carregar uma dependência obrigatória.
In Go, panic is a built-in function that stops the ordinary flow:
This code prints a and then stops before printing b:
Panicking in Go should be used sparingly. There are two prominent cases, one to signal a programmer error (e.g., sql.Register that panics if the driver is nil or has already been register) and another where our application fails to create a mandatory dependency. Hence, exceptional conditions that lead us to stop the application. In most other cases, error management should be done with a function that returns a proper error type as the last return argument.
Ignorando quando embrulhar um erro (#49)
TL;DR
Embrulhar um erro permite marcar um erro e/ou fornecer contexto adicional. No entanto, o agrupamento de erros cria um acoplamento potencial, pois disponibiliza o erro de origem para o chamador. Se você quiser evitar isso, não use a agrupamento automático de erros.
Since Go 1.13, the %w directive allows us to wrap errors conveniently. Error wrapping is about wrapping or packing an error inside a wrapper container that also makes the source error available. In general, the two main use cases for error wrapping are the following:
- Adding additional context to an error
- Marking an error as a specific error
When handling an error, we can decide to wrap it. Wrapping is about adding additional context to an error and/or marking an error as a specific type. If we need to mark an error, we should create a custom error type. However, if we just want to add extra context, we should use fmt.Errorf with the %w directive as it doesn’t require creating a new error type. Yet, error wrapping creates potential coupling as it makes the source error available for the caller. If we want to prevent it, we shouldn’t use error wrapping but error transformation, for example, using fmt.Errorf with the %v directive.
Comparando um tipo de erro de forma imprecisa (#50)
TL;DR
Se você usar o agrupamento de erros do Go 1.13 com a diretiva %w e fmt.Errorf, a comparação de um erro com um tipo deverá ser feita usando errors.As. Caso contrário, se o erro retornado que você deseja verificar for embrulhado, as verificações falharão.
Comparando um valor de erro incorretamente (#51)
TL;DR
Se você usar o agrupamento de erros do Go 1.13 com a diretiva %w e fmt.Errorf, a comparação de um erro ou de um valor deverá ser feita usando errors.As. Caso contrário, se o erro retornado que você deseja verificar for embrulhado, as verificações falharão.
A sentinel error is an error defined as a global variable:
In general, the convention is to start with Err followed by the error type: here, ErrFoo. A sentinel error conveys an expected error, an error that clients will expect to check. As general guidelines:
- Expected errors should be designed as error values (sentinel errors):
var ErrFoo = errors.New("foo"). - Unexpected errors should be designed as error types:
type BarError struct { ... }, withBarErrorimplementing theerrorinterface.
If we use error wrapping in our application with the %w directive and fmt.Errorf, checking an error against a specific value should be done using errors.Is instead of ==. Thus, even if the sentinel error is wrapped, errors.Is can recursively unwrap it and compare each error in the chain against the provided value.
Lidando com um erro duas vezes (#52)
TL;DR
Na maioria das situações, um erro deve ser tratado apenas uma vez. Registrar um erro é tratar um erro. Portanto, você deve escolher entre registrar ou retornar um erro. Em muitos casos, o embrulho automático de erros é a solução, pois permite fornecer contexto adicional a um erro e retornar o erro de origem.
Handling an error multiple times is a mistake made frequently by developers, not specifically in Go. This can cause situations where the same error is logged multiple times make debugging harder.
Let's remind us that handling an error should be done only once. Logging an error is handling an error. Hence, we should either log or return an error. By doing this, we simplify our code and gain better insights into the error situation. Using error wrapping is the most convenient approach as it allows us to propagate the source error and add context to an error.
Não tratando de um erro (#53)
TL;DR
Ignorar um erro, seja durante uma chamada de função ou em uma função defer, deve ser feito explicitamente usando o identificador em branco. Caso contrário, os futuros leitores poderão ficar confusos sobre se foi intencional ou um erro.
Não tratando erros de defer (#54)
TL;DR
Em muitos casos, você não deve ignorar um erro retornado por uma função defer. Manipule-o diretamente ou propague-o para o chamador, dependendo do contexto. Se você quiser ignorá-lo, use o identificador em branco.
Consider the following code:
From a maintainability perspective, the code can lead to some issues. Let’s consider a new reader looking at it. This reader notices that notify returns an error but that the error isn’t handled by the parent function. How can they guess whether or not handling the error was intentional? How can they know whether the previous developer forgot to handle it or did it purposely?
For these reasons, when we want to ignore an error, there's only one way to do it, using the blank identifier (_):
In terms of compilation and run time, this approach doesn’t change anything compared to the first piece of code. But this new version makes explicit that we aren’t interested in the error. Also, we can add a comment that indicates the rationale for why an error is ignored:
// At-most once delivery.
// Hence, it's accepted to miss some of them in case of errors.
_ = notify()
Concurrency: Foundations
Misturando simultaneidade e paralelismo (#55)
TL;DR
Compreender as diferenças fundamentais entre simultaneidade e paralelismo é a base do conhecimento do desenvolvedor Go. A simultaneidade tem a ver com estrutura, enquanto o paralelismo tem a ver com execução.
Concurrency and parallelism are not the same:
- Concurrency is about structure. We can change a sequential implementation into a concurrent one by introducing different steps that separate concurrent goroutines can tackle.
- Meanwhile, parallelism is about execution. We can use parallism at the steps level by adding more parallel goroutines.
In summary, concurrency provides a structure to solve a problem with parts that may be parallelized. Therefore, concurrency enables parallelism.
Pensar que a simultaneidade é sempre mais rápida (#56)
TL;DR
Para ser um desenvolvedor proficiente, você deve reconhecer que a simultaneidade nem sempre é mais rápida. As soluções que envolvem a paralelização de cargas de trabalho mínimas podem não ser necessariamente mais rápidas do que uma implementação sequencial. A avaliação comparativa de soluções sequenciais versus soluções simultâneas deve ser a forma de validar suposições.
Read the full section here.
Ficar confuso sobre quando usar canais ou mutexes (#57)
TL;DR
Estar ciente das interações goroutine também pode ser útil ao decidir entre canais e mutexes. Em geral, goroutines paralelas requerem sincronização e, portanto, mutexes. Por outro lado, goroutines simultâneas geralmente requerem coordenação e orquestração e, portanto, canais.
Given a concurrency problem, it may not always be clear whether we can implement a solution using channels or mutexes. Because Go promotes sharing memory by communication, one mistake could be to always force the use of channels, regardless of the use case. However, we should see the two options as complementary.
When should we use channels or mutexes? We will use the example in the next figure as a backbone. Our example has three different goroutines with specific relationships:
- G1 and G2 are parallel goroutines. They may be two goroutines executing the same function that keeps receiving messages from a channel, or perhaps two goroutines executing the same HTTP handler at the same time.
- On the other hand, G1 and G3 are concurrent goroutines, as are G2 and G3. All the goroutines are part of an overall concurrent structure, but G1 and G2 perform the first step, whereas G3 does the next step.
In general, parallel goroutines have to synchronize: for example, when they need to access or mutate a shared resource such as a slice. Synchronization is enforced with mutexes but not with any channel types (not with buffered channels). Hence, in general, synchronization between parallel goroutines should be achieved via mutexes.
Conversely, in general, concurrent goroutines have to coordinate and orchestrate. For example, if G3 needs to aggregate results from both G1 and G2, G1 and G2 need to signal to G3 that a new intermediate result is available. This coordination falls under the scope of communication—therefore, channels.
Regarding concurrent goroutines, there’s also the case where we want to transfer the ownership of a resource from one step (G1 and G2) to another (G3); for example, if G1 and G2 are enriching a shared resource and at some point, we consider this job as complete. Here, we should use channels to signal that a specific resource is ready and handle the ownership transfer.
Mutexes and channels have different semantics. Whenever we want to share a state or access a shared resource, mutexes ensure exclusive access to this resource. Conversely, channels are a mechanic for signaling with or without data (chan struct{} or not). Coordination or ownership transfer should be achieved via channels. It’s important to know whether goroutines are parallel or concurrent because, in general, we need mutexes for parallel goroutines and channels for concurrent ones.
Não entender os problemas de corrida (corridas de dados vs. condições de corrida e o modelo de memória Go) (#58)
TL;DR
Ser proficiente em simultaneidade também significa compreender que corridas de dados e condições de corrida são conceitos diferentes. As corridas de dados ocorrem quando várias goroutines acessam simultaneamente o mesmo local de memória e pelo menos uma delas está gravando. Enquanto isso, estar livre de disputa de dados não significa necessariamente execução determinística. Quando um comportamento depende da sequência ou do tempo de eventos que não podem ser controlados, esta é uma condição de corrida.
Race problems can be among the hardest and most insidious bugs a programmer can face. As Go developers, we must understand crucial aspects such as data races and race conditions, their possible impacts, and how to avoid them.
Data Race
A data race occurs when two or more goroutines simultaneously access the same memory location and at least one is writing. In this case, the result can be hazardous. Even worse, in some situations, the memory location may end up holding a value containing a meaningless combination of bits.
We can prevent a data race from happening using different techniques. For example:
- Using the
sync/atomicpackage - In synchronizing the two goroutines with an ad hoc data structure like a mutex
- Using channels to make the two goroutines communicating to ensure that a variable is updated by only one goroutine at a time
Race Condition
Depending on the operation we want to perform, does a data-race-free application necessarily mean a deterministic result? Not necessarily.
A race condition occurs when the behavior depends on the sequence or the timing of events that can’t be controlled. Here, the timing of events is the goroutines’ execution order.
In summary, when we work in concurrent applications, it’s essential to understand that a data race is different from a race condition. A data race occurs when multiple goroutines simultaneously access the same memory location and at least one of them is writing. A data race means unexpected behavior. However, a data-race-free application doesn’t necessarily mean deterministic results. An application can be free of data races but still have behavior that depends on uncontrolled events (such as goroutine execution, how fast a message is published to a channel, or how long a call to a database lasts); this is a race condition. Understanding both concepts is crucial to becoming proficient in designing concurrent applications.
Não compreender os impactos de simultaneidade de um tipo de carga de trabalho (#59)
TL;DR
Ao criar um determinado número de goroutines, considere o tipo de carga de trabalho. Criar goroutines vinculadas à CPU significa limitar esse número próximo à variável GOMAXPROCS (baseado por padrão no número de núcleos de CPU no host). A criação de goroutines vinculadas a E/S depende de outros fatores, como o sistema externo.
In programming, the execution time of a workload is limited by one of the following:
- The speed of the CPU—For example, running a merge sort algorithm. The workload is called CPU-bound.
- The speed of I/O—For example, making a REST call or a database query. The workload is called I/O-bound.
- The amount of available memory—The workload is called memory-bound.
Note
The last is the rarest nowadays, given that memory has become very cheap in recent decades. Hence, this section focuses on the two first workload types: CPU- and I/O-bound.
If the workload executed by the workers is I/O-bound, the value mainly depends on the external system. Conversely, if the workload is CPU-bound, the optimal number of goroutines is close to the number of available CPU cores (a best practice can be to use runtime.GOMAXPROCS). Knowing the workload type (I/O or CPU) is crucial when designing concurrent applications.
Incompreensão dos contextos Go (#60)
TL;DR
Os contextos Go também são um dos pilares da simultaneidade em Go. Um contexto permite que você carregue um prazo, um sinal de cancelamento e/ou uma lista de valores-chave.
https://pkg.go.dev/context
A Context carries a deadline, a cancellation signal, and other values across API boundaries.
Deadline
A deadline refers to a specific point in time determined with one of the following:
- A
time.Durationfrom now (for example, in 250 ms) - A
time.Time(for example, 2023-02-07 00:00:00 UTC)
The semantics of a deadline convey that an ongoing activity should be stopped if this deadline is met. An activity is, for example, an I/O request or a goroutine waiting to receive a message from a channel.
Cancellation signals
Another use case for Go contexts is to carry a cancellation signal. Let’s imagine that we want to create an application that calls CreateFileWatcher(ctx context.Context, filename string) within another goroutine. This function creates a specific file watcher that keeps reading from a file and catches updates. When the provided context expires or is canceled, this function handles it to close the file descriptor.
Context values
The last use case for Go contexts is to carry a key-value list. What’s the point of having a context carrying a key-value list? Because Go contexts are generic and mainstream, there are infinite use cases.
For example, if we use tracing, we may want different subfunctions to share the same correlation ID. Some developers may consider this ID too invasive to be part of the function signature. In this regard, we could also decide to include it as part of the provided context.
Catching a context cancellation
The context.Context type exports a Done method that returns a receive-only notification channel: <-chan struct{}. This channel is closed when the work associated with the context should be canceled. For example,
- The Done channel related to a context created with
context.WithCancelis closed when the cancel function is called. - The Done channel related to a context created with
context.WithDeadlineis closed when the deadline has expired.
One thing to note is that the internal channel should be closed when a context is canceled or has met a deadline, instead of when it receives a specific value, because the closure of a channel is the only channel action that all the consumer goroutines will receive. This way, all the consumers will be notified once a context is canceled or a deadline is reached.
In summary, to be a proficient Go developer, we have to understand what a context is and how to use it. In general, a function that users wait for should take a context, as doing so allows upstream callers to decide when calling this function should be aborted.
Concurrency: Practice
Propagando um contexto impróprio (#61)
TL;DR
Compreender as condições em que um contexto pode ser cancelado deve ser importante ao propagá-lo: por exemplo, um manipulador HTTP cancelando o contexto quando a resposta for enviada.
In many situations, it is recommended to propagate Go contexts. However, context propagation can sometimes lead to subtle bugs, preventing subfunctions from being correctly executed.
Let’s consider the following example. We expose an HTTP handler that performs some tasks and returns a response. But just before returning the response, we also want to send it to a Kafka topic. We don’t want to penalize the HTTP consumer latency-wise, so we want the publish action to be handled asynchronously within a new goroutine. We assume that we have at our disposal a publish function that accepts a context so the action of publishing a message can be interrupted if the context is canceled, for example. Here is a possible implementation:
func handler(w http.ResponseWriter, r *http.Request) {
response, err := doSomeTask(r.Context(), r)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
go func() {
err := publish(r.Context(), response)
// Do something with err
}()
writeResponse(response)
}
What’s wrong with this piece of code? We have to know that the context attached to an HTTP request can cancel in different conditions:
- When the client’s connection closes
- In the case of an HTTP/2 request, when the request is canceled
- When the response has been written back to the client
In the first two cases, we probably handle things correctly. For example, if we get a response from doSomeTask but the client has closed the connection, it’s probably OK to call publish with a context already canceled so the message isn’t published. But what about the last case?
When the response has been written to the client, the context associated with the request will be canceled. Therefore, we are facing a race condition:
- If the response is written after the Kafka publication, we both return a response and publish a message successfully
- However, if the response is written before or during the Kafka publication, the message shouldn’t be published.
In the latter case, calling publish will return an error because we returned the HTTP response quickly.
Note
From Go 1.21, there is a way to create a new context without cancel. context.WithoutCancel returns a copy of parent that is not canceled when parent is canceled.
In summary, propagating a context should be done cautiously.
Iniciando uma goroutine sem saber quando interrompê-la (#62)
TL;DR
Evitar vazamentos significa estar ciente de que sempre que uma goroutine for iniciada, você deve ter um plano para interrompê-la eventualmente.
Goroutines are easy and cheap to start—so easy and cheap that we may not necessarily have a plan for when to stop a new goroutine, which can lead to leaks. Not knowing when to stop a goroutine is a design issue and a common concurrency mistake in Go.
Let’s discuss a concrete example. We will design an application that needs to watch some external configuration (for example, using a database connection). Here’s a first implementation:
func main() {
newWatcher()
// Run the application
}
type watcher struct { /* Some resources */ }
func newWatcher() {
w := watcher{}
go w.watch() // Creates a goroutine that watches some external configuration
}
The problem with this code is that when the main goroutine exits (perhaps because of an OS signal or because it has a finite workload), the application is stopped. Hence, the resources created by watcher aren’t closed gracefully. How can we prevent this from happening?
One option could be to pass to newWatcher a context that will be canceled when main returns:
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
newWatcher(ctx)
// Run the application
}
func newWatcher(ctx context.Context) {
w := watcher{}
go w.watch(ctx)
}
We propagate the context created to the watch method. When the context is canceled, the watcher struct should close its resources. However, can we guarantee that watch will have time to do so? Absolutely not—and that’s a design flaw.
The problem is that we used signaling to convey that a goroutine had to be stopped. We didn’t block the parent goroutine until the resources had been closed. Let’s make sure we do:
func main() {
w := newWatcher()
defer w.close()
// Run the application
}
func newWatcher() watcher {
w := watcher{}
go w.watch()
return w
}
func (w watcher) close() {
// Close the resources
}
Instead of signaling watcher that it’s time to close its resources, we now call this close method, using defer to guarantee that the resources are closed before the application exits.
In summary, let’s be mindful that a goroutine is a resource like any other that must eventually be closed to free memory or other resources. Starting a goroutine without knowing when to stop it is a design issue. Whenever a goroutine is started, we should have a clear plan about when it will stop. Last but not least, if a goroutine creates resources and its lifetime is bound to the lifetime of the application, it’s probably safer to wait for this goroutine to complete before exiting the application. This way, we can ensure that the resources can be freed.
Não ter cuidado com goroutines e variáveis de loop (#63)
Warning
Este erro não é mais relevante no Go 1.22 (detalhes).
Esperando um comportamento determinístico usando seleção e canais (#64)
TL;DR
Compreender que com select vários canais escolhe o caso aleatoriamente se múltiplas opções forem possíveis evita fazer suposições erradas que podem levar a erros sutis de simultaneidade.
One common mistake made by Go developers while working with channels is to make wrong assumptions about how select behaves with multiple channels.
For example, let's consider the following case (disconnectCh is a unbuffered channel):
go func() {
for i := 0; i < 10; i++ {
messageCh <- i
}
disconnectCh <- struct{}{}
}()
for {
select {
case v := <-messageCh:
fmt.Println(v)
case <-disconnectCh:
fmt.Println("disconnection, return")
return
}
}
If we run this example multiple times, the result will be random:
Instead of consuming the 10 messages, we only received a few of them. What’s the reason? It lies in the specification of the select statement with multiple channels (https:// go.dev/ref/spec):
Quote
If one or more of the communications can proceed, a single one that can proceed is chosen via a uniform pseudo-random selection.
Unlike a switch statement, where the first case with a match wins, the select statement selects randomly if multiple options are possible.
This behavior might look odd at first, but there’s a good reason for it: to prevent possible starvation. Suppose the first possible communication chosen is based on the source order. In that case, we may fall into a situation where, for example, we only receive from one channel because of a fast sender. To prevent this, the language designers decided to use a random selection.
When using select with multiple channels, we must remember that if multiple options are possible, the first case in the source order does not automatically win. Instead, Go selects randomly, so there’s no guarantee about which option will be chosen. To overcome this behavior, in the case of a single producer goroutine, we can use either unbuffered channels or a single channel.
Não usar canais de notificação (#65)
TL;DR
Envie notificações usando um tipo chan struct{}.
Channels are a mechanism for communicating across goroutines via signaling. A signal can be either with or without data.
Let’s look at a concrete example. We will create a channel that will notify us whenever a certain disconnection occurs. One idea is to handle it as a chan bool:
Now, let’s say we interact with an API that provides us with such a channel. Because it’s a channel of Booleans, we can receive either true or false messages. It’s probably clear what true conveys. But what does false mean? Does it mean we haven’t been disconnected? And in this case, how frequently will we receive such a signal? Does it mean we have reconnected? Should we even expect to receive false? Perhaps we should only expect to receive true messages.
If that’s the case, meaning we don’t need a specific value to convey some information, we need a channel without data. The idiomatic way to handle it is a channel of empty structs: chan struct{}.
Não usar canais nulos (#66)
TL;DR
O uso de canais nulos deve fazer parte do seu conjunto de ferramentas de simultaneidade porque permite remover casos de instruções select, por exemplo.
What should this code do?
ch is a chan int type. The zero value of a channel being nil, ch is nil. The goroutine won’t panic; however, it will block forever.
The principle is the same if we send a message to a nil channel. This goroutine blocks forever:
Then what’s the purpose of Go allowing messages to be received from or sent to a nil channel? For example, we can use nil channels to implement an idiomatic way to merge two channels:
func merge(ch1, ch2 <-chan int) <-chan int {
ch := make(chan int, 1)
go func() {
for ch1 != nil || ch2 != nil { // Continue if at least one channel isn’t nil
select {
case v, open := <-ch1:
if !open {
ch1 = nil // Assign ch1 to a nil channel once closed
break
}
ch <- v
case v, open := <-ch2:
if !open {
ch2 = nil // Assigns ch2 to a nil channel once closed
break
}
ch <- v
}
}
close(ch)
}()
return ch
}
This elegant solution relies on nil channels to somehow remove one case from the select statement.
Let’s keep this idea in mind: nil channels are useful in some conditions and should be part of the Go developer’s toolset when dealing with concurrent code.
Ficar intrigado com o tamanho do canal (#67)
TL;DR
Decida cuidadosamente o tipo de canal correto a ser usado, considerando o problema. Somente canais sem buffer oferecem fortes garantias de sincronização. Para canais em buffer, você deve ter um bom motivo para especificar um tamanho de canal diferente de um.
An unbuffered channel is a channel without any capacity. It can be created by either omitting the size or providing a 0 size:
With an unbuffered channel (sometimes called a synchronous channel), the sender will block until the receiver receives data from the channel.
Conversely, a buffered channel has a capacity, and it must be created with a size greater than or equal to 1:
With a buffered channel, a sender can send messages while the channel isn’t full. Once the channel is full, it will block until a receiver goroutine receives a message:
The first send isn’t blocking, whereas the second one is, as the channel is full at this stage.
What's the main difference between unbuffered and buffered channels:
- An unbuffered channel enables synchronization. We have the guarantee that two goroutines will be in a known state: one receiving and another sending a message.
- A buffered channel doesn’t provide any strong synchronization. Indeed, a producer goroutine can send a message and then continue its execution if the channel isn’t full. The only guarantee is that a goroutine won’t receive a message before it is sent. But this is only a guarantee because of causality (you don’t drink your coffee before you prepare it).
If we need a buffered channel, what size should we provide?
The default value we should use for buffered channels is its minimum: 1. So, we may approach the problem from this standpoint: is there any good reason not to use a value of 1? Here’s a list of possible cases where we should use another size:
- While using a worker pooling-like pattern, meaning spinning a fixed number of goroutines that need to send data to a shared channel. In that case, we can tie the channel size to the number of goroutines created.
- When using channels for rate-limiting problems. For example, if we need to enforce resource utilization by bounding the number of requests, we should set up the channel size according to the limit.
If we are outside of these cases, using a different channel size should be done cautiously. Let’s bear in mind that deciding about an accurate queue size isn’t an easy problem:
Martin Thompson
Queues are typically always close to full or close to empty due to the differences in pace between consumers and producers. They very rarely operate in a balanced middle ground where the rate of production and consumption is evenly matched.
Esquecendo os possíveis efeitos colaterais da formatação de strings (#68)
TL;DR
Estar ciente de que a formatação de strings pode levar à chamada de funções existentes significa estar atento a possíveis impasses e outras disputas de dados.
It’s pretty easy to forget the potential side effects of string formatting while working in a concurrent application.
etcd data race
github.com/etcd-io/etcd/pull/7816 shows an example of an issue where a map's key was formatted based on a mutable values from a context.
Deadlock
Can you see what the problem is in this code with a Customer struct exposing an UpdateAge method and implementing the fmt.Stringer interface?
type Customer struct {
mutex sync.RWMutex // Uses a sync.RWMutex to protect concurrent accesses
id string
age int
}
func (c *Customer) UpdateAge(age int) error {
c.mutex.Lock() // Locks and defers unlock as we update Customer
defer c.mutex.Unlock()
if age < 0 { // Returns an error if age is negative
return fmt.Errorf("age should be positive for customer %v", c)
}
c.age = age
return nil
}
func (c *Customer) String() string {
c.mutex.RLock() // Locks and defers unlock as we read Customer
defer c.mutex.RUnlock()
return fmt.Sprintf("id %s, age %d", c.id, c.age)
}
The problem here may not be straightforward. If the provided age is negative, we return an error. Because the error is formatted, using the %s directive on the receiver, it will call the String method to format Customer. But because UpdateAge already acquires the mutex lock, the String method won’t be able to acquire it. Hence, this leads to a deadlock situation. If all goroutines are also asleep, it leads to a panic.
One possible solution is to restrict the scope of the mutex lock:
func (c *Customer) UpdateAge(age int) error {
if age < 0 {
return fmt.Errorf("age should be positive for customer %v", c)
}
c.mutex.Lock() <1>
defer c.mutex.Unlock()
c.age = age
return nil
}
Yet, such an approach isn't always possible. In these conditions, we have to be extremely careful with string formatting.
Another approach is to access the id field directly:
func (c *Customer) UpdateAge(age int) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if age < 0 {
return fmt.Errorf("age should be positive for customer id %s", c.id)
}
c.age = age
return nil
}
In concurrent applications, we should remain cautious about the possible side effects of string formatting.
Criando corridas de dados com acréscimo (#69)
TL;DR
As chamadas append nem sempre são isentas de disputa de dados; portanto, não deve ser usado simultaneamente em uma slice compartilhada.
Should adding an element to a slice using append is data-race-free? Spoiler: it depends.
Do you believe this example has a data race?
s := make([]int, 1)
go func() { // In a new goroutine, appends a new element on s
s1 := append(s, 1)
fmt.Println(s1)
}()
go func() { // Same
s2 := append(s, 1)
fmt.Println(s2)
}()
The answer is no.
In this example, we create a slice with make([]int, 1). The code creates a one-length, one-capacity slice. Thus, because the slice is full, using append in each goroutine returns a slice backed by a new array. It doesn’t mutate the existing array; hence, it doesn’t lead to a data race.
Now, let’s run the same example with a slight change in how we initialize s. Instead of creating a slice with a length of 1, we create it with a length of 0 but a capacity of 1. How about this new example? Does it contain a data race?
s := make([]int, 0, 1)
go func() {
s1 := append(s, 1)
fmt.Println(s1)
}()
go func() {
s2 := append(s, 1)
fmt.Println(s2)
}()
The answer is yes. We create a slice with make([]int, 0, 1). Therefore, the array isn’t full. Both goroutines attempt to update the same index of the backing array (index 1), which is a data race.
How can we prevent the data race if we want both goroutines to work on a slice containing the initial elements of s plus an extra element? One solution is to create a copy of s.
We should remember that using append on a shared slice in concurrent applications can lead to a data race. Hence, it should be avoided.
Usando mutexes imprecisamente com slices e maps (#70)
TL;DR
Lembrar que slices e maps são ponteiros pode evitar corridas comuns de dados.
Let's implement a Cache struct used to handle caching for customer balances. This struct will contain a map of balances per customer ID and a mutex to protect concurrent accesses:
Next, we add an AddBalance method that mutates the balances map. The mutation is done in a critical section (within a mutex lock and a mutex unlock):
func (c *Cache) AddBalance(id string, balance float64) {
c.mu.Lock()
c.balances[id] = balance
c.mu.Unlock()
}
Meanwhile, we have to implement a method to calculate the average balance for all the customers. One idea is to handle a minimal critical section this way:
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
balances := c.balances // Creates a copy of the balances map
c.mu.RUnlock()
sum := 0.
for _, balance := range balances { // Iterates over the copy, outside of the critical section
sum += balance
}
return sum / float64(len(balances))
}
What's the problem with this code?
If we run a test using the -race flag with two concurrent goroutines, one calling AddBalance (hence mutating balances) and another calling AverageBalance, a data race occurs. What’s the problem here?
Internally, a map is a runtime.hmap struct containing mostly metadata (for example, a counter) and a pointer referencing data buckets. So, balances := c.balances doesn’t copy the actual data. Therefore, the two goroutines perform operations on the same data set, and one mutates it. Hence, it's a data race.
One possible solution is to protect the whole AverageBalance function:
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
defer c.mu.RUnlock() // Unlocks when the function returns
sum := 0.
for _, balance := range c.balances {
sum += balance
}
return sum / float64(len(c.balances))
}
Another option, if the iteration operation isn’t lightweight, is to work on an actual copy of the data and protect only the copy:
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
m := make(map[string]float64, len(c.balances)) // Copies the map
for k, v := range c.balances {
m[k] = v
}
c.mu.RUnlock()
sum := 0.
for _, balance := range m {
sum += balance
}
return sum / float64(len(m))
}
Once we have made a deep copy, we release the mutex. The iterations are done on the copy outside of the critical section.
In summary, we have to be careful with the boundaries of a mutex lock. In this section, we have seen why assigning an existing map (or an existing slice) to a map isn’t enough to protect against data races. The new variable, whether a map or a slice, is backed by the same data set. There are two leading solutions to prevent this: protect the whole function, or work on a copy of the actual data. In all cases, let’s be cautious when designing critical sections and make sure the boundaries are accurately defined.
Uso indevido sync.WaitGroup (#71)
TL;DR
Para usar com precisão sync.WaitGroup, chame o método Add antes de ativar goroutines.
Esquecendo sync.Cond (#72)
TL;DR
Você pode enviar notificações repetidas para vários goroutines com sync.Cond.
Não usando errgroup (#73)
TL;DR
Você pode sincronizar um grupo de goroutines e lidar com erros e contextos com o pacote errgroup.
Copiando um tipo sync (#74)
TL;DR
Tipos sync não devem ser copiados.
Standard Library
Fornecendo uma duração de tempo errada (#75)
TL;DR
Seja cauteloso com funções que aceitam um arquivo time.Duration. Mesmo que a passagem de um número inteiro seja permitida, tente usar a API time para evitar qualquer possível confusão.
Many common functions in the standard library accept a time.Duration, which is an alias for the int64 type. However, one time.Duration unit represents one nanosecond, instead of one millisecond, as commonly seen in other programming languages. As a result, passing numeric types instead of using the time.Duration API can lead to unexpected behavior.
A developer with experience in other languages might assume that the following code creates a new time.Ticker that delivers ticks every second, given the value 1000:
However, because 1,000 time.Duration units = 1,000 nanoseconds, ticks are delivered every 1,000 nanoseconds = 1 microsecond, not every second as assumed.
We should always use the time.Duration API to avoid confusion and unexpected behavior:
time.After e vazamentos de memória (#76)
TL;DR
Evitar chamadas para funções time.After repetidas (como loops ou manipuladores HTTP) pode evitar pico de consumo de memória. Os recursos criados por time.After são liberados somente quando o cronômetro expira.
Developers often use time.After in loops or HTTP handlers repeatedly to implement the timing function. But it can lead to unintended peak memory consumption due to the delayed release of resources, just like the following code:
func consumer(ch <-chan Event) {
for {
select {
case event := <-ch:
handle(event)
case <-time.After(time.Hour):
log.Println("warning: no messages received")
}
}
}
The source code of the function time.After is as follows:
As we see, it returns receive-only channel.
When time.After is used in a loop or repeated context, a new channel is created in each iteration. If these channels are not properly closed or if their associated timers are not stopped, they can accumulate and consume memory. The resources associated with each timer and channel are only released when the timer expires or the channel is closed.
To avoid this happening, We can use context's timeout setting instead of time.After, like below:
func consumer(ch <-chan Event) {
for {
ctx, cancel := context.WithTimeout(context.Background(), time.Hour)
select {
case event := <-ch:
cancel()
handle(event)
case <-ctx.Done():
log.Println("warning: no messages received")
}
}
}
We can also use time.NewTimer like so:
func consumer(ch <-chan Event) {
timerDuration := 1 * time.Hour
timer := time.NewTimer(timerDuration)
for {
timer.Reset(timerDuration)
select {
case event := <-ch:
handle(event)
case <-timer.C:
log.Println("warning: no messages received")
}
}
}
Lidando com erros comuns JSON (#77)
- Comportamento inesperado devido à incorporação de tipo
Tenha cuidado ao usar campos incorporados em estruturas Go. Fazer isso pode levar a bugs sorrateiros, como um campo time.Time incorporado que implementa a interface json.Marshaler, substituindo assim o comportamento de empacotamento padrão.
- JSON e o relógio monotônico
Ao comparar duas estruturas time.Time, lembre-se de que time.Time contém um relógio de parede e um relógio monotônico, e a comparação usando o operador == é feita em ambos os relógios.
- Map de
any
Para evitar suposições erradas ao fornecer um map ao desempacotar (unmarshaling) dados JSON, lembre-se de que os valores numéricos são convertidos para float64 por padrão.
Erros comuns de SQL (#78)
- Esquecer
sql.Opennão necessariamente estabelece conexões com um banco de dados
Esquecer sql.Open não necessariamente estabelece conexões com um banco de dados
Chame o método Ping ou PingContext se precisar testar sua configuração e garantir que um banco de dados esteja acessível.
- Esquecendo o pool de conexões
Configure os parâmetros de conexão do banco de dados para aplicativos de nível de produção.
- Não usar declarações preparadas
O uso de instruções preparadas em SQL torna as consultas mais eficientes e seguras.
- Tratamento incorreto de valores nulos
Lide com colunas anuláveis em tabelas usando ponteiros ou tipos sql.NullXXX.
- Não tratando de erros de iteração de linhas
Chame o método Err de sql.Rows iterações posteriores à linha para garantir que você não perdeu nenhum erro ao preparar a próxima linha.
Não fechando recursos transitórios (body HTTP, sql.Rows e os.File) (#79)
TL;DR
Eventualmente feche todas as estruturas implementadas io.Closer para evitar possíveis vazamentos.
Esquecendo a instrução return após responder a uma solicitação HTTP (#80)
TL;DR
Para evitar comportamentos inesperados nas implementações do manipulador HTTP, certifique-se de não perder a instrução return se quiser que um manipulador pare após http.Error.
Consider the following HTTP handler that handles an error from foo using http.Error:
func handler(w http.ResponseWriter, req *http.Request) {
err := foo(req)
if err != nil {
http.Error(w, "foo", http.StatusInternalServerError)
}
_, _ = w.Write([]byte("all good"))
w.WriteHeader(http.StatusCreated)
}
If we run this code and err != nil, the HTTP response would be:
The response contains both the error and success messages, and also the first HTTP status code, 500. There would also be a warning log indicating that we attempted to write the status code multiple times:
The mistake in this code is that http.Error does not stop the handler's execution, which means the success message and status code get written in addition to the error. Beyond an incorrect response, failing to return after writing an error can lead to the unwanted execution of code and unexpected side-effects. The following code adds the return statement following the http.Error and exhibits the desired behavior when ran:
func handler(w http.ResponseWriter, req *http.Request) {
err := foo(req)
if err != nil {
http.Error(w, "foo", http.StatusInternalServerError)
return // Adds the return statement
}
_, _ = w.Write([]byte("all good"))
w.WriteHeader(http.StatusCreated)
}
Usando o cliente e servidor HTTP padrão (#81)
TL;DR
Para aplicativos de nível de produção, não use as implementações de cliente e servidor HTTP padrão. Essas implementações não possuem tempos limite e comportamentos que deveriam ser obrigatórios na produção.
Teste
Não categorizar testes (tags de construção, variáveis de ambiente e modo abreviado) (#82)
TL;DR
Categorizar testes usando sinalizadores de construção, variáveis de ambiente ou modo curto torna o processo de teste mais eficiente. Você pode criar categorias de teste usando sinalizadores de construção ou variáveis de ambiente (por exemplo, testes de unidade versus testes de integração) e diferenciar testes curtos de testes de longa duração para decidir quais tipos de testes executar.
Não habilitando a bandeira de corrida (#83)
TL;DR
A ativação do sinalizador -race é altamente recomendada ao escrever aplicativos simultâneos. Isso permite que você detecte possíveis corridas de dados que podem levar a bugs de software.
In Go, the race detector isn’t a static analysis tool used during compilation; instead, it’s a tool to find data races that occur at runtime. To enable it, we have to enable the -race flag while compiling or running a test. For example:
Once the race detector is enabled, the compiler instruments the code to detect data races. Instrumentation refers to a compiler adding extra instructions: here, tracking all memory accesses and recording when and how they occur.
Enabling the race detector adds an overhead in terms of memory and execution time; hence, it's generally recommended to enable it only during local testing or continuous integration, not production.
If a race is detected, Go raises a warning. For example:
Runnig this code with the -race logs the following warning:
==================
WARNING: DATA RACE
Write at 0x00c000026078 by goroutine 7: # (1)
main.main.func1()
/tmp/app/main.go:9 +0x4e
Previous read at 0x00c000026078 by main goroutine: # (2)
main.main()
/tmp/app/main.go:10 +0x88
Goroutine 7 (running) created at: # (3)
main.main()
/tmp/app/main.go:9 +0x7a
==================
- Indicates that goroutine 7 was writing
- Indicates that the main goroutine was reading
- Indicates when the goroutine 7 was created
Let’s make sure we are comfortable reading these messages. Go always logs the following:
- The concurrent goroutines that are incriminated: here, the main goroutine and goroutine 7.
- Where accesses occur in the code: in this case, lines 9 and 10.
- When these goroutines were created: goroutine 7 was created in main().
In addition, if a specific file contains tests that lead to data races, we can exclude it from race detection using the !race build tag:
Não usar modos de execução de teste (paralelo e aleatório) (#84)
TL;DR
Usar o sinalizador -parallel é uma forma eficiente de acelerar testes, especialmente os de longa duração. Use o sinalizador -shuffle para ajudar a garantir que um conjunto de testes não se baseie em suposições erradas que possam ocultar bugs.
Não usar testes baseados em tabela (#85)
TL;DR
Os testes baseados em tabelas são uma maneira eficiente de agrupar um conjunto de testes semelhantes para evitar a duplicação de código e facilitar o manuseio de atualizações futuras.
Dormindo em testes unitários (#86)
TL;DR
Evite interrupções usando a sincronização para tornar o teste menos instável e mais robusto. Se a sincronização não for possível, considere uma abordagem de nova tentativa.
Não lidar com a API de tempo de forma eficiente (#87)
TL;DR
Entender como lidar com funções usando a API time é outra maneira de tornar um teste menos complicado. Você pode usar técnicas padrão, como lidar com o tempo como parte de uma dependência oculta ou solicitar que os clientes o forneçam.
Não usar pacotes de utilitários de teste ( httptest e iotest) (#88)
- O pacote
httptesté útil para lidar com aplicativos HTTP. Ele fornece um conjunto de utilitários para testar clientes e servidores.
- O pacote
iotestajuda a escrever io.Reader e testar se um aplicativo é tolerante a erros.
Escrevendo benchmarks imprecisos (#89)
TL;DR
Regarding benchmarks:
- Use métodos de tempo para preservar a precisão de um benchmark.
- Aumentar o tempo de teste ou usar ferramentas como o benchstat pode ser útil ao lidar com micro-benchmarks.
- Tenha cuidado com os resultados de um micro-benchmark se o sistema que executa o aplicativo for diferente daquele que executa o micro-benchmark.
- Certifique-se de que a função em teste cause um efeito colateral, para evitar que as otimizações do compilador enganem você sobre os resultados do benchmark.
- Para evitar o efeito observador, force um benchmark a recriar os dados usados por uma função vinculada à CPU.
Leia a seção completa aqui.
Não explorando todos os recursos de teste do Go (#90)
- Cobertura de código
Use a cobertura de código com o sinalizador -coverprofile para ver rapidamente qual parte do código precisa de mais atenção.
- Testando de um pacote diferente
Coloque os testes unitários em um pacote diferente para impor testes de escrita que se concentrem em um comportamento exposto, não em internos.
- Funções utilitárias
O tratamento de erros usando a variável *testing.T em vez do clássico if err != nil torna o código mais curto e fácil de ler.
- Configuração e desmontagem
Você pode usar funções de setup e teardown para configurar um ambiente complexo, como no caso de testes de integração.
Não usar fuzzing (erro da comunidade)
TL;DR
Fuzzing é uma estratégia eficiente para detectar entradas aleatórias, inesperadas ou malformadas em funções e métodos complexos, a fim de descobrir vulnerabilidades, bugs ou até mesmo travamentos potenciais.
Credits: @jeromedoucet
Otimizações
Não entendendo os caches da CPU (#91)
- Arquitetura da CPU
Compreender como usar caches de CPU é importante para otimizar aplicativos vinculados à CPU porque o cache L1 é cerca de 50 a 100 vezes mais rápido que a memória principal.
- Linha de cache
Estar consciente do conceito de linha de cache é fundamental para entender como organizar dados em aplicativos com uso intensivo de dados. Uma CPU não busca memória palavra por palavra; em vez disso, geralmente copia um bloco de memória para uma linha de cache de 64 bytes. Para aproveitar ao máximo cada linha de cache individual, imponha a localidade espacial.
- Slice de estruturas vs. estrutura de slices
- Previsibilidade
Tornar o código previsível para a CPU também pode ser uma forma eficiente de otimizar certas funções. Por exemplo, uma passada unitária ou constante é previsível para a CPU, mas uma passada não unitária (por exemplo, uma lista vinculada) não é previsível.
- Política de posicionamento de cache
Para evitar um avanço crítico e, portanto, utilizar apenas uma pequena parte do cache, esteja ciente de que os caches são particionados.
Escrevendo código simultâneo que leva a compartilhamento falso (#92)
TL;DR
Saber que níveis mais baixos de caches de CPU não são compartilhados entre todos os núcleos ajuda a evitar padrões que degradam o desempenho, como compartilhamento falso ao escrever código de simultaneidade. Compartilhar memória é uma ilusão.
Leia a seção completa aqui.
Não levando em consideração o paralelismo no nível de instrução (#93)
TL;DR
Use o ILP para otimizar partes específicas do seu código para permitir que uma CPU execute tantas instruções paralelas quanto possível. Identificar perigos nos dados é uma das etapas principais.
Não estar ciente do alinhamento dos dados (#94)
TL;DR
Você pode evitar erros comuns lembrando que no Go os tipos básicos são alinhados com seu próprio tamanho. Por exemplo, tenha em mente que reorganizar os campos de uma estrutura por tamanho em ordem decrescente pode levar a estruturas mais compactas (menos alocação de memória e potencialmente uma melhor localidade espacial).
Não entendendo stack vs. heap (#95)
TL;DR
Compreender as diferenças fundamentais entre heap e pilha também deve fazer parte do seu conhecimento básico ao otimizar um aplicativo Go. As alocações de pilha são quase gratuitas, enquanto as alocações de heap são mais lentas e dependem do GC para limpar a memória.
Não saber como reduzir alocações (mudança de API, otimizações de compilador e sync.Pool) (#96)
TL;DR
A redução das alocações também é um aspecto essencial da otimização de um aplicativo Go. Isso pode ser feito de diferentes maneiras, como projetar a API cuidadosamente para evitar compartilhamento, compreender as otimizações comuns do compilador Go e usar sync.Pool.
Não dependendo do inlining (#97)
TL;DR
Use a técnica de inlining de caminho rápido para reduzir com eficiência o tempo amortizado para chamar uma função.
Não usar ferramentas de diagnóstico Go (#98)
TL;DR
Confie na criação de perfil e no rastreador de execução para entender o desempenho de um aplicativo e as partes a serem otimizadas.
Leia a seção completa aqui.
Não entendendo como funciona o GC (#99)
TL;DR
Compreender como ajustar o GC pode levar a vários benefícios, como lidar com aumentos repentinos de carga com mais eficiência.
Não entendendo os impactos da execução do Go no Docker e Kubernetes (#100)
TL;DR
Para ajudar a evitar a limitação da CPU quando implantado no Docker e no Kubernetes, lembre-se de que Go não reconhece CFS.
By default, GOMAXPROCS is set to the number of OS-apparent logical CPU cores.
When running some Go code inside Docker and Kubernetes, we must know that Go isn't CFS-aware (github.com/golang/go/issues/33803). Therefore, GOMAXPROCS isn't automatically set to the value of spec.containers.resources.limits.cpu (see Kubernetes Resource Management for Pods and Containers); instead, it's set to the number of logical cores on the host machine. The main implication is that it can lead to an increased tail latency in some specific situations.
One solution is to rely on uber-go/automaxprocs that automatically set GOMAXPROCS to match the Linux container CPU quota.
Community
Thanks to all the contributors: