Thinking concurrency is always faster

A misconception among many developers is believing that a concurrent solution is always faster than a sequential one. This couldn’t be more wrong. The overall performance of a solution depends on many factors, such as the efficiency of our code structure (concurrency), which parts can be tackled in parallel, and the level of contention among the computation units. This post reminds us about some fundamental knowledge of concurrency in Go; then we will see a concrete example where a concurrent solution isn’t necessarily faster.
Go Scheduling
A thread is the smallest unit of processing that an OS can perform. If a process wants to execute multiple actions simultaneously, it spins up multiple threads. These threads can be:
- Concurrent — Two or more threads can start, run, and complete in overlapping time periods.
- Parallel — The same task can be executed multiple times at once.
The OS is responsible for scheduling the thread’s processes optimally so that:
- All the threads can consume CPU cycles without being starved for too much time.
- The workload is distributed as evenly as possible among the different CPU cores.
Note
The word thread can also have a different meaning at a CPU level. Each physical core can be composed of multiple logical cores (the concept of hyper-threading), and a logical core is also called a thread. In this post, when we use the word thread, we mean the unit of processing, not a logical core.
A CPU core executes different threads. When it switches from one thread to another, it executes an operation called context switching. The active thread consuming CPU cycles was in an executing state and moves to a runnable state, meaning it’s ready to be executed pending an available core. Context switching is considered an expensive operation because the OS needs to save the current execution state of a thread before the switch (such as the current register values).
As Go developers, we can’t create threads directly, but we can create goroutines, which can be thought of as application-level threads. However, whereas an OS thread is context-switched on and off a CPU core by the OS, a goroutine is context-switched on and off an OS thread by the Go runtime. Also, compared to an OS thread, a goroutine has a smaller memory footprint: 2 KB for goroutines from Go 1.4. An OS thread depends on the OS, but, for example, on Linux/x86–32, the default size is 2 MB (see https://man7.org/linux/man-pages/man3/pthread_create.3.html). Having a smaller size makes context switching faster.
Note
Context switching a goroutine versus a thread is about 80% to 90% faster, depending on the architecture.
Let’s now discuss how the Go scheduler works to overview how goroutines are handled. Internally, the Go scheduler uses the following terminology (see proc.go):
- G — Goroutine
- M — OS thread (stands for machine)
- P — CPU core (stands for processor)
Each OS thread (M) is assigned to a CPU core (P) by the OS scheduler. Then, each goroutine (G) runs on an M. The GOMAXPROCS variable defines the limit of Ms in charge of executing user-level code simultaneously. But if a thread is blocked in a system call (for example, I/O), the scheduler can spin up more Ms. As of Go 1.5, GOMAXPROCS is by default equal to the number of available CPU cores.
A goroutine has a simpler lifecycle than an OS thread. It can be doing one of the following:
- Executing — The goroutine is scheduled on an M and executing its instructions.
- Runnable — The goroutine is waiting to be in an executing state.
- Waiting — The goroutine is stopped and pending something completing, such as a system call or a synchronization operation (such as acquiring a mutex).
There’s one last stage to understand about the implementation of Go scheduling: when a goroutine is created but cannot be executed yet; for example, all the other Ms are already executing a G. In this scenario, what will the Go runtime do about it? The answer is queuing. The Go runtime handles two kinds of queues: one local queue per P and a global queue shared among all the Ps.
Figure 1 shows a given scheduling situation on a four-core machine with GOMAXPROCS equal to 4. The parts are the logical cores (Ps), goroutines (Gs), OS threads (Ms), local queues, and global queue:
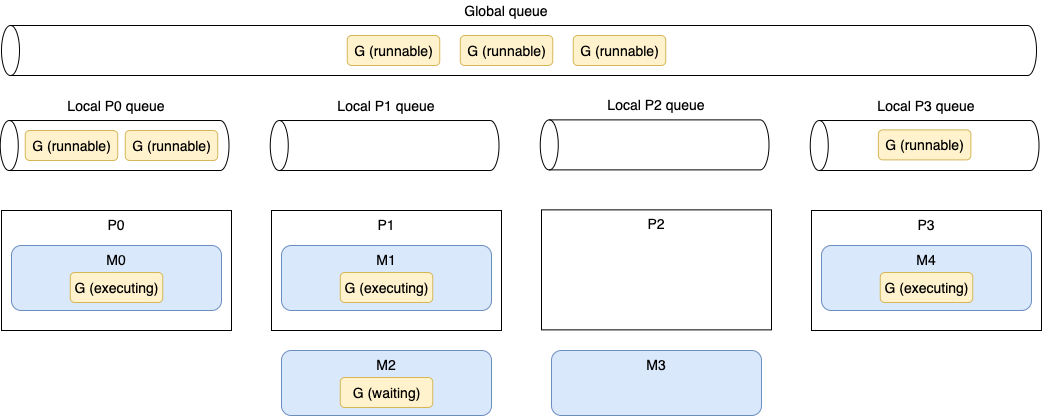
First, we can see five Ms, whereas GOMAXPROCS is set to 4. But as we mentioned, if needed, the Go runtime can create more OS threads than the GOMAXPROCS value.
P0, P1, and P3 are currently busy executing Go runtime threads. But P2 is presently idle as M3 is switched off P2, and there’s no goroutine to be executed. This isn’t a good situation because six runnable goroutines are pending being executed, some in the global queue and some in other local queues. How will the Go runtime handle this situation? Here’s the scheduling implementation in pseudocode (see proc.go):
runtime.schedule() {
// Only 1/61 of the time, check the global runnable queue for a G.
// If not found, check the local queue.
// If not found,
// Try to steal from other Ps.
// If not, check the global runnable queue.
// If not found, poll network.
}
Every sixty-first execution, the Go scheduler will check whether goroutines from the global queue are available. If not, it will check its local queue. Meanwhile, if both the global and local queues are empty, the Go scheduler can pick up goroutines from other local queues. This principle in scheduling is called work stealing, and it allows an underutilized processor to actively look for another processor’s goroutines and steal some.
One last important thing to mention: prior to Go 1.14, the scheduler was cooperative, which meant a goroutine could be context-switched off a thread only in specific blocking cases (for example, channel send or receive, I/O, waiting to acquire a mutex). Since Go 1.14, the Go scheduler is now preemptive: when a goroutine is running for a specific amount of time (10 ms), it will be marked preemptible and can be context-switched off to be replaced by another goroutine. This allows a long-running job to be forced to share CPU time.
Now that we understand the fundamentals of scheduling in Go, let’s look at a concrete example: implementing a merge sort in a parallel manner.
Parallel Merge Sort
First, let’s briefly review how the merge sort algorithm works. Then we will implement a parallel version. Note that the objective isn’t to implement the most efficient version but to support a concrete example showing why concurrency isn’t always faster.
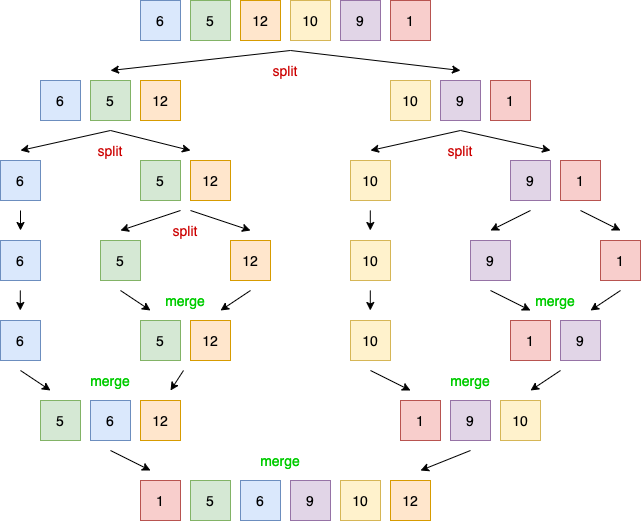
The merge sort algorithm works by breaking a list repeatedly into two sublists until each sublist consists of a single element and then merging these sublists so that the result is a sorted list (see figure 2). Each split operation splits the list into two sublists, whereas the merge operation merges two sublists into a sorted list.
Here is the sequential implementation of this algorithm. We don’t include all of the code as it’s not the main point of this section:
func sequentialMergesort(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
sequentialMergesort(s[:middle]) // First half
sequentialMergesort(s[middle:]) // Second half
merge(s, middle) // Merges the two halves
}
func merge(s []int, middle int) {
// ...
}
This algorithm has a structure that makes it open to concurrency. Indeed, as each sequentialMergesort operation works on an independent set of data that doesn’t need to be fully copied (here, an independent view of the underlying array using slicing), we could distribute this workload among the CPU cores by spinning up each sequentialMergesort operation in a different goroutine. Let’s write a first parallel implementation:
func parallelMergesortV1(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() { // Spins up the first half of the work in a goroutine
defer wg.Done()
parallelMergesortV1(s[:middle])
}()
go func() { // Spins up the second half of the work in a goroutine
defer wg.Done()
parallelMergesortV1(s[middle:])
}()
wg.Wait()
merge(s, middle) // Merges the halves
}
In this version, each half of the workload is handled in a separate goroutine. The parent goroutine waits for both parts by using sync.WaitGroup. Hence, we call the Wait method before the merge operation.
We now have a parallel version of the merge sort algorithm. Therefore, if we run a benchmark to compare this version against the sequential one, the parallel version should be faster, correct? Let’s run it on a four-core machine with 10,000 elements:
Surprisingly, the parallel version is almost an order of magnitude slower. How can we explain this result? How is it possible that a parallel version that distributes a workload across four cores is slower than a sequential version running on a single machine? Let’s analyze the problem.
If we have a slice of, say, 1,024 elements, the parent goroutine will spin up two goroutines, each in charge of handling a half consisting of 512 elements. Each of these goroutines will spin up two new goroutines in charge of handling 256 elements, then 128, and so on, until we spin up a goroutine to compute a single element.
If the workload that we want to parallelize is too small, meaning we’re going to compute it too fast, the benefit of distributing a job across cores is destroyed: the time it takes to create a goroutine and have the scheduler execute it is much too high compared to directly merging a tiny number of items in the current goroutine. Although goroutines are lightweight and faster to start than threads, we can still face cases where a workload is too small.
So what can we conclude from this result? Does it mean the merge sort algorithm cannot be parallelized? Wait, not so fast.
Let’s try another approach. Because merging a tiny number of elements within a new goroutine isn’t efficient, let’s define a threshold. This threshold will represent how many elements a half should contain in order to be handled in a parallel manner. If the number of elements in the half is fewer than this value, we will handle it sequentially. Here’s a new version:
const max = 2048 // Defines the threshold
func parallelMergesortV2(s []int) {
if len(s) <= 1 {
return
}
if len(s) <= max {
sequentialMergesort(s) // Calls our initial sequential version
} else { // If bigger than the threshold, keeps the parallel version
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
parallelMergesortV2(s[:middle])
}()
go func() {
defer wg.Done()
parallelMergesortV2(s[middle:])
}()
wg.Wait()
merge(s, middle)
}
}
If the number of elements in the s slice is smaller than max, we call the sequential version. Otherwise, we keep calling our parallel implementation. Does this approach impact the result? Yes, it does:
Benchmark_sequentialMergesort-4 2278993555 ns/op
Benchmark_parallelMergesortV1-4 17525998709 ns/op
Benchmark_parallelMergesortV2-4 1313010260 ns/op
Our v2 parallel implementation is more than 40% faster than the sequential one, thanks to this idea of defining a threshold to indicate when parallel should be more efficient than sequential.
Note
Why did I set the threshold to 2,048? Because it was the optimal value for this specific workload on my machine. In general, such magic values should be defined carefully with benchmarks (running on an execution environment similar to production). It’s also pretty interesting to note that running the same algorithm in a programming language that doesn’t implement the concept of goroutines has an impact on the value. For example, running the same example in Java using threads means an optimal value closer to 8,192. This tends to illustrate how goroutines are more efficient than threads.
Conclusion
We have seen throughout this post the fundamental concepts of scheduling in Go: the differences between a thread and a goroutine and how the Go runtime schedules goroutines. Meanwhile, using the parallel merge sort example, we illustrated that concurrency isn’t always necessarily faster. As we have seen, spinning up goroutines to handle minimal workloads (merging only a small set of elements) demolishes the benefit we could get from parallelism.
So, where should we go from here? We must keep in mind that concurrency isn’t always faster and shouldn’t be considered the default way to go for all problems. First, it makes things more complex. Also, modern CPUs have become incredibly efficient at executing sequential code and predictable code. For example, a superscalar processor can parallelize instruction execution over a single core with high efficiency.
Does this mean we shouldn’t use concurrency? Of course not. However, it’s essential to keep these conclusions in mind. If we’re not sure that a parallel version will be faster, the right approach may be to start with a simple sequential version and build from there using profiling (mistake #98, “Not using Go diagnostics tooling”) and benchmarks (mistake #89, “Writing inaccurate benchmarks”), for example. It can be the only way to ensure that a concurrent implementation is worth it.